Избирательная система РФ в цифрах
Общее количество зарегистрированных в РФ избирателей составляет около 100 млн человек (величина варьирует от одних выборов к другим, причем не всегда понятным образом).
Общее количество избирательных участков в стране составляет немного менее 100 тыс. Таким образом, в среднем на один избирательный участок приходится примерно 1000 человек. Типичный размер избирательного участка в городах — 1500-2500 избирателей, в сельской местности — несколько сотен. Существуют «закрытые» участки (военные части, больницы, тюрьмы, суда торгового флота), в которых обычно немного избирателей и высокая (до 100%) явка.
Участковые избирательные комиссии (УИК) подчинены территориальным избирательным комиссиям (ТИК); их в РФ примерно 2750. При проведении голосований по мажоритарной системе формируются избирательные округа: в небольших субъектах Федерации — по одному, в крупных — по несколько; на выборах в Госдуму 2007 г. их было 153 в РФ, в том числе 10 в Москве, на выборах в Мосгордуму 2009 г. — 17 (в Москве).
Начиная примерно с 2003 года (с выборов в Государственную Думу 4-го созыва) все результаты выборов с детализацией вплоть до избирательных участков публикуются на сайте ЦИК www.izbirkom.ru.
Введение
Тема статистического анализа результатов выборов вновь стала популярной в связи с недавними выборами в Мосгордуму. Как и после федеральных выборов 2007-2008 года, отношение к самой идее статистического анализа выборов неоднозначное. Некоторые эксперты вообще высказываются в том духе, что неспециалистам в эту тему соваться не стоит. Так, вице-президент Центра политической конъюнктуры Виталий Иванов говорит: «Не надо математикам со своими моделями лезть в политику, анализировать выборы, придумывать какие-то свои версии. Это просто смешно, когда математик рассуждает о выборах. Давайте еще биолога спросим! Или узнаем, что по поводу результатов выборов думает физик-ядерщик! У них, наверное, тоже найдутся идеи, как высчитать, какой на самом деле должен быть результат. Я считаю, всерьез обсуждать здесь нечего!» (www.polit.ru/news/2009/10/19/mathematics.html).
У автора по этому вопросу другое мнение. Пока для результатов выборов не введена какая-либо специальная суверенная арифметика, любой человек имеет право анализировать эти результаты и делать свои выводы. На самом деле статистические подходы к анализу результатов выборов в России используются с начала 1990-х годов, с тех самых пор, как появились свободные выборы. Среди основополагающих работ на эту тему (большая подборка ссылок на различные материалы приведена в (1)) можно отметить исследования А.А. Собянина и В.Г.Суховольского (2). В настоящее время исследованиями на эту тему занимаются М. Мягков, П. Ордешук и Д. Шакин (3), У. Мебейн (4), А. Любарев и А.Бузин (5). После федеральных выборов 2007/2008 года также вышла статья председателя ЦИК В. Чурова с соавторами (6), оппонирующая книге Мягкова, Ордешука и Шакина и публикациям автора настоящей статьи в Livejournal. Хороший обзор результатов недавних выборов с точки зрения теории вероятностей написал А. Шень (7).
В этой статье я хотел бы предложить вниманию читателей результаты своих исследований статистики выборов, начатых после выборов в Государственную Думу РФ в декабре 2007 г. Материалом для исследования являются исключительно данные голосований по избирательным участкам, территориальным комиссиям, округам и субъектам Федерации, полученные с сайта Центризбиркома (см. врезку). По сути каждые выборы представляют собой гигантский эксперимент, дающий огромный (N~106 чисел для федеральных выборов, ~105 чисел для выборов в Москве) полный (без пропусков) структурированный массив данных. При этом количество отсчетов данных N настолько велико, что этот массив можно разбивать на большое количество подкатегорий, и каждая из этих категорий будет по-прежнему содержать статистически значимое количество отсчетов данных. Эта работа не строгое статистическое исследование, а скорее поиск «срезов» данных, позволяющих выявить интересные особенности выборов.
Статистические особенности результатов российских выборов 2007-2009 гг.
Первой и наиболее заметной особенностью выборов последних лет является зависимость результатов голосования от явки.
Для наглядности начнем сразу с конкретных примеров.
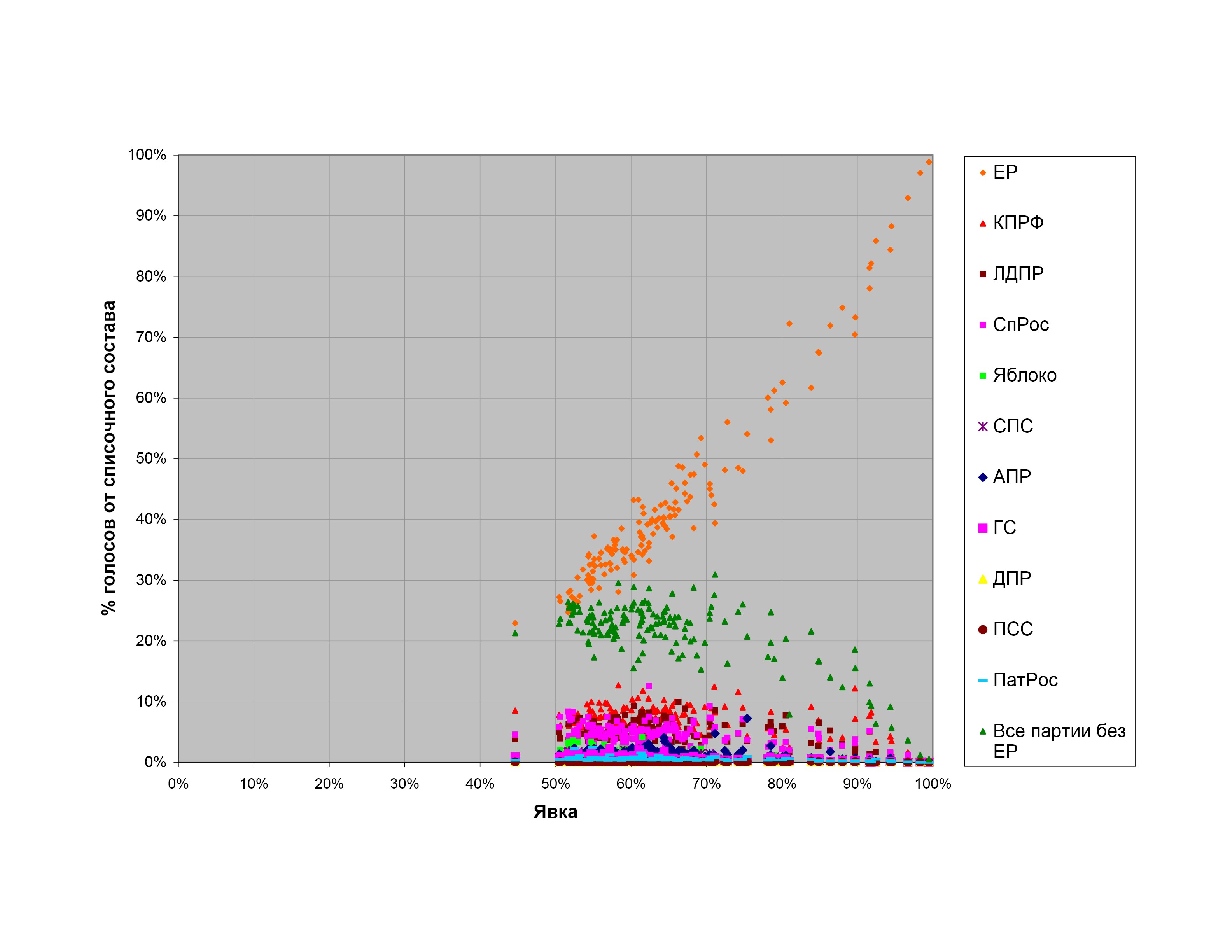
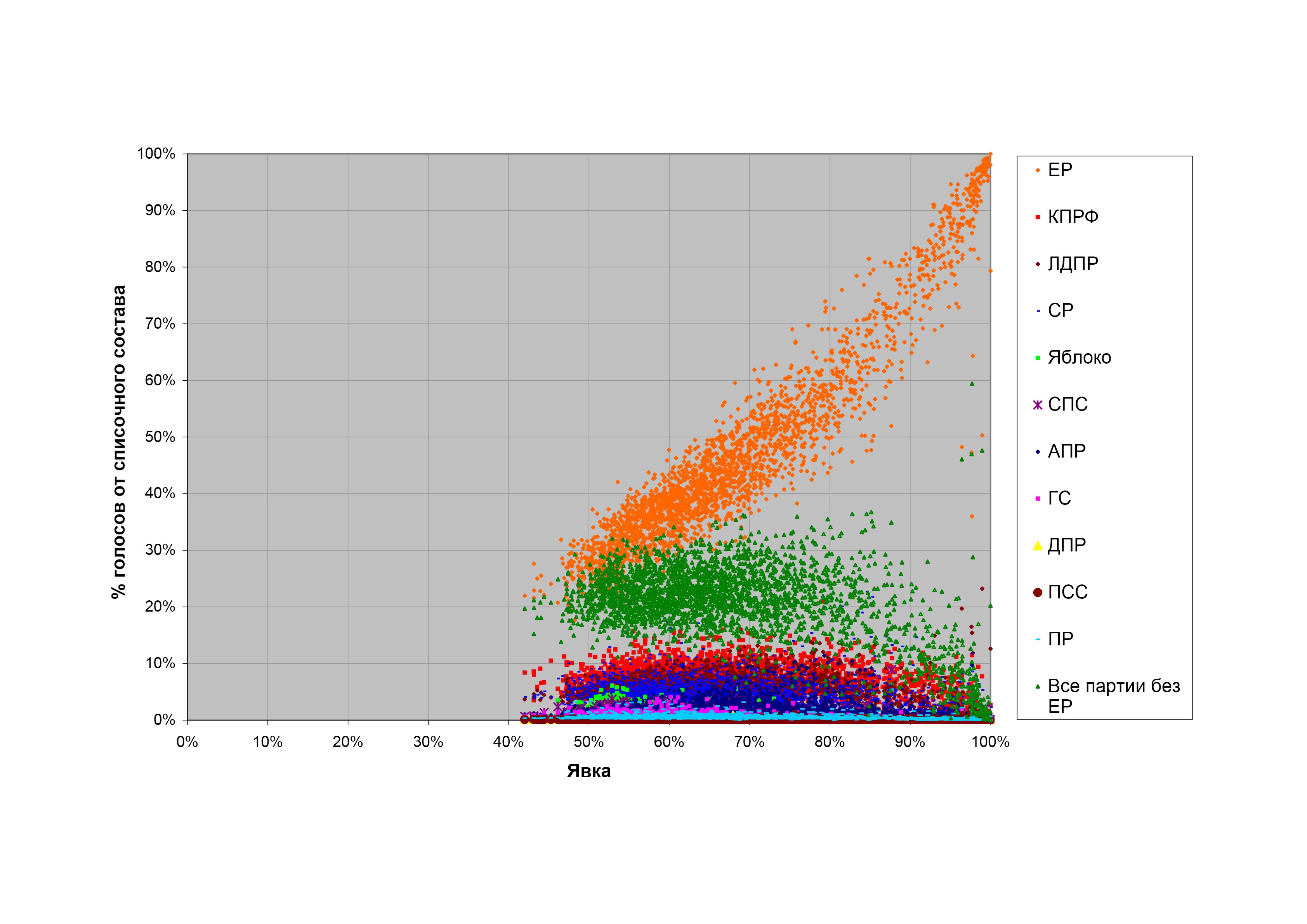
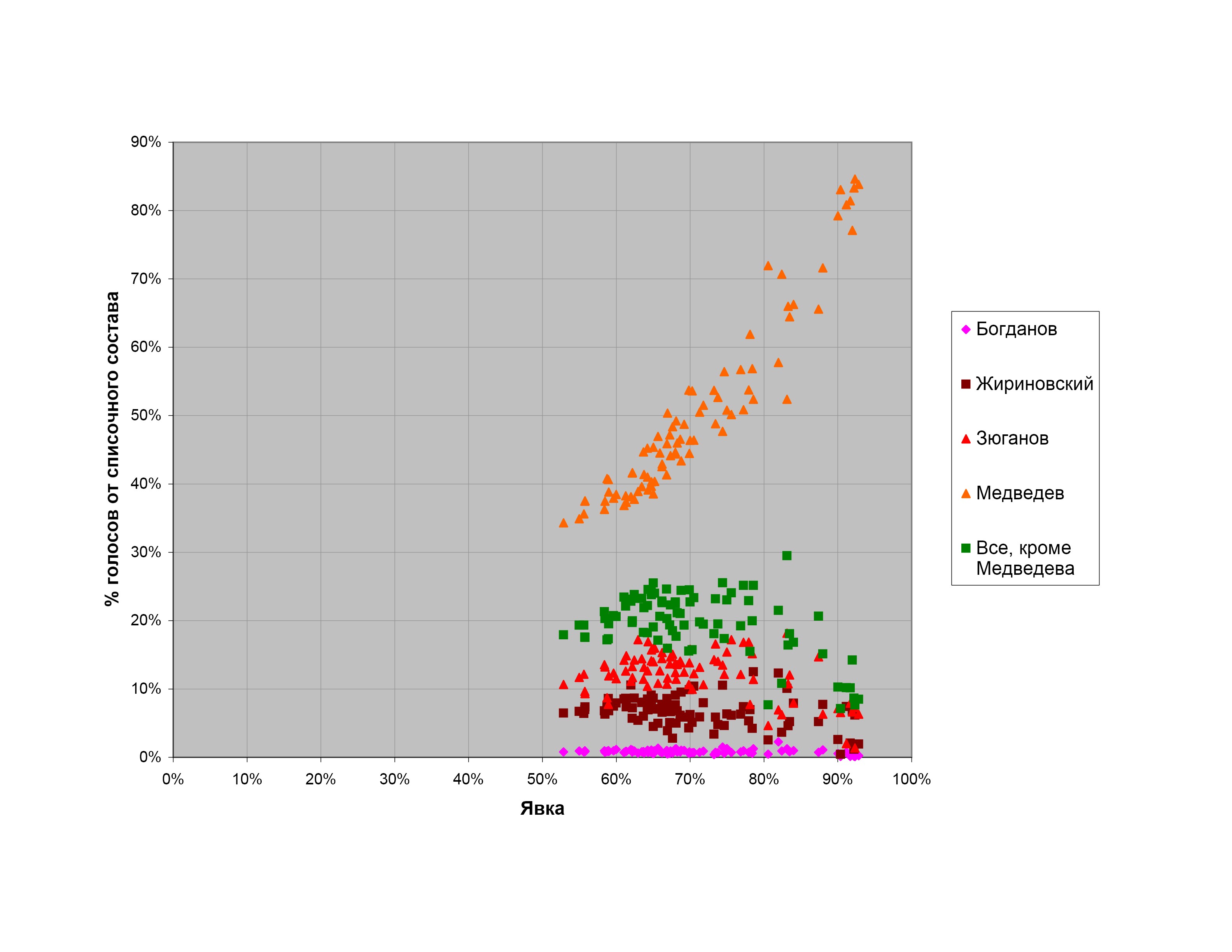
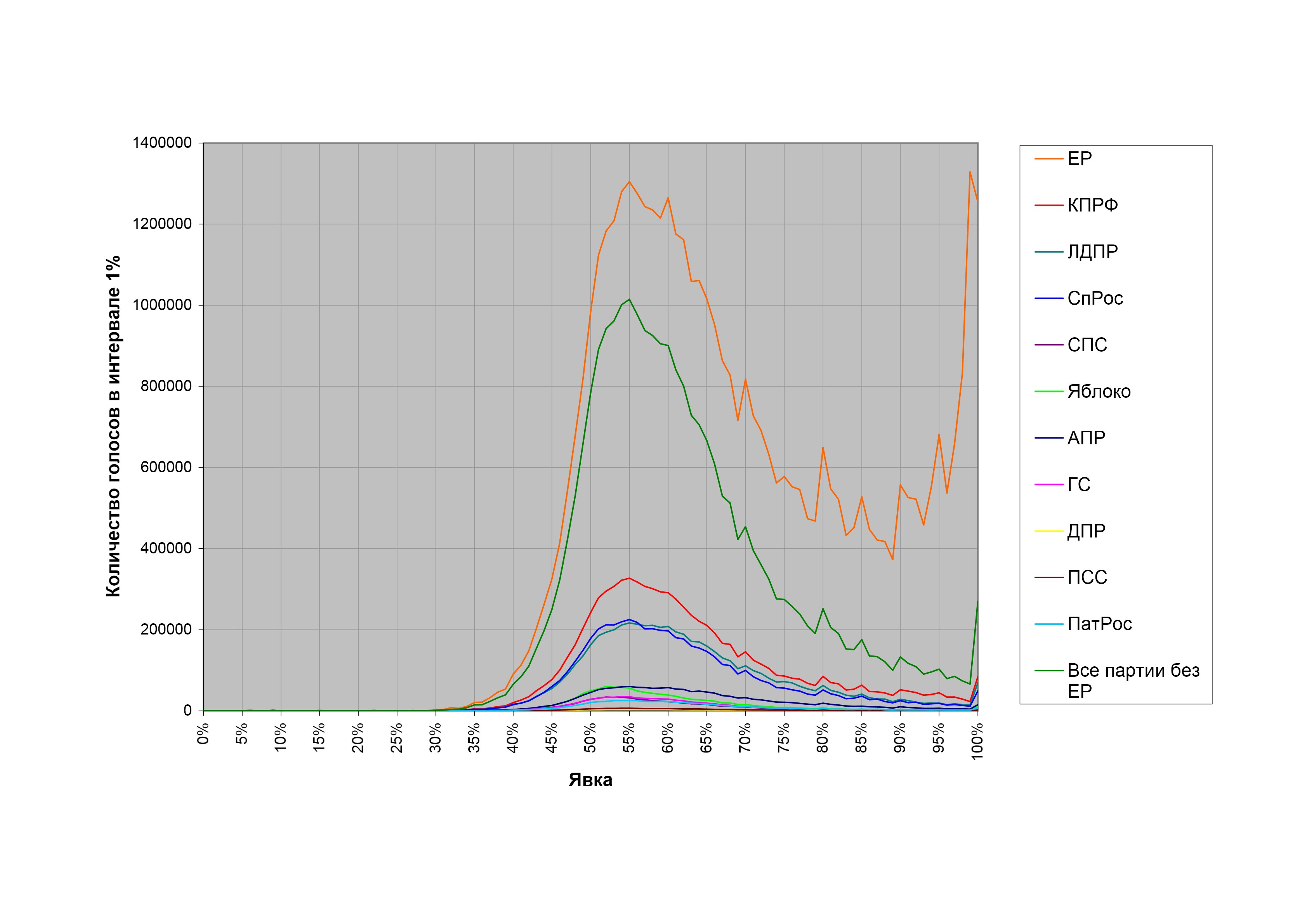
На рис. 1-4 приведены диаграммы распределения голосов за различные кандидатуры (партии — на выборах в представительные органы, кандидатов — на президентских выборах) на думских выборах 2007 г., президентских выборах 2008 г. и выборах в Мосгордуму 2009 г. на различных уровнях детализации данных. На всех графиках по оси абсцисс отложена явка в процентах, а по оси ординат — процентная доля избирателей, проголосовавших за данную кандидатуру, от общего числа зарегистрированных избирателей (списочного состава) на избирательных участках с такой явкой (явка округляется вниз до целого числа процентов).
Все четыре диаграммы, несмотря на то, что относятся к разным выборам и имеют разную степень детализации, обладают общими особенностями.
При малых явках имеется более или менее выраженный участок, где результаты разных кандидатов растут пропорционально друг другу (точки ложатся на прямые, проходящие через начало координат). Это означает, что при изменении явки количество голосующих за все кандидатуры растет пропорционально, а процентные доли сторонников разных партий среди пришедших на выборы остаются постоянными.
При дальнейшем росте явки количество голосующих за все кандидатуры, кроме кандидатуры власти, остается постоянным, а все дополнительные голоса, возникающие от прироста явки, отходят к кандидатуре власти.
Наконец, при высоких явках доли голосов за все кандидатуры, кроме кандидатуры власти, начинают падать, а все потерянные ими голоса вкупе с дополнительными голосами от роста явки отходят к кандидатуре власти.
Поведение a) соответствует так называемому «правилу Собянина-Суховольского», предложенному еще в 1990-е годы в качестве критерия честного подсчета голосов на выборах (см. (1)). Оно возникает, например, если вероятность прихода избирателей на участок не зависит от их политических предпочтений.
Поведение b) можно объяснить различными способами. Одно возможное объяснение: избиратели оппозиционных кандидатов демонстрируют на выборах высокую активность и в большинстве случаев приходят на выборы все до одного, а избиратели кандидатуры власти пассивны, и их доля среди пришедших голосовать меняется в широких пределах. Другое объяснение: начиная с некоторой явки, весь прирост явки и все дополнительные голоса, поданные за партию власти, являются результатом вброса, приписок или административного давления (последний вариант в некотором смысле смыкается с первым объяснением — если избиратели кандидатуры власти ходят на выборы из-под административной палки).
Наконец, поведение с) может быть объяснено, например, тем, что избирательные участки с высокой явкой находятся в местностях или местах, где за кандидатуру власти голосуют охотно, а за остальных кандидатов — мало и редко. Другое возможное объяснение — отъем голосов у «прочих» кандидатов и приписки в пользу кандидатуры власти.
Чтобы понять, какие из этих механизмов больше соответствуют действительности, обратимся к другим особенностям статистики голосований.
Распределение избирательных участков по явке
Хотя явка не является официальным отчетным параметром и не фигурирует в итогах выборов, публикуемых избирательными комиссиями, неформально к ней относятся очень внимательно. Это дает порой весьма неожиданные результаты.
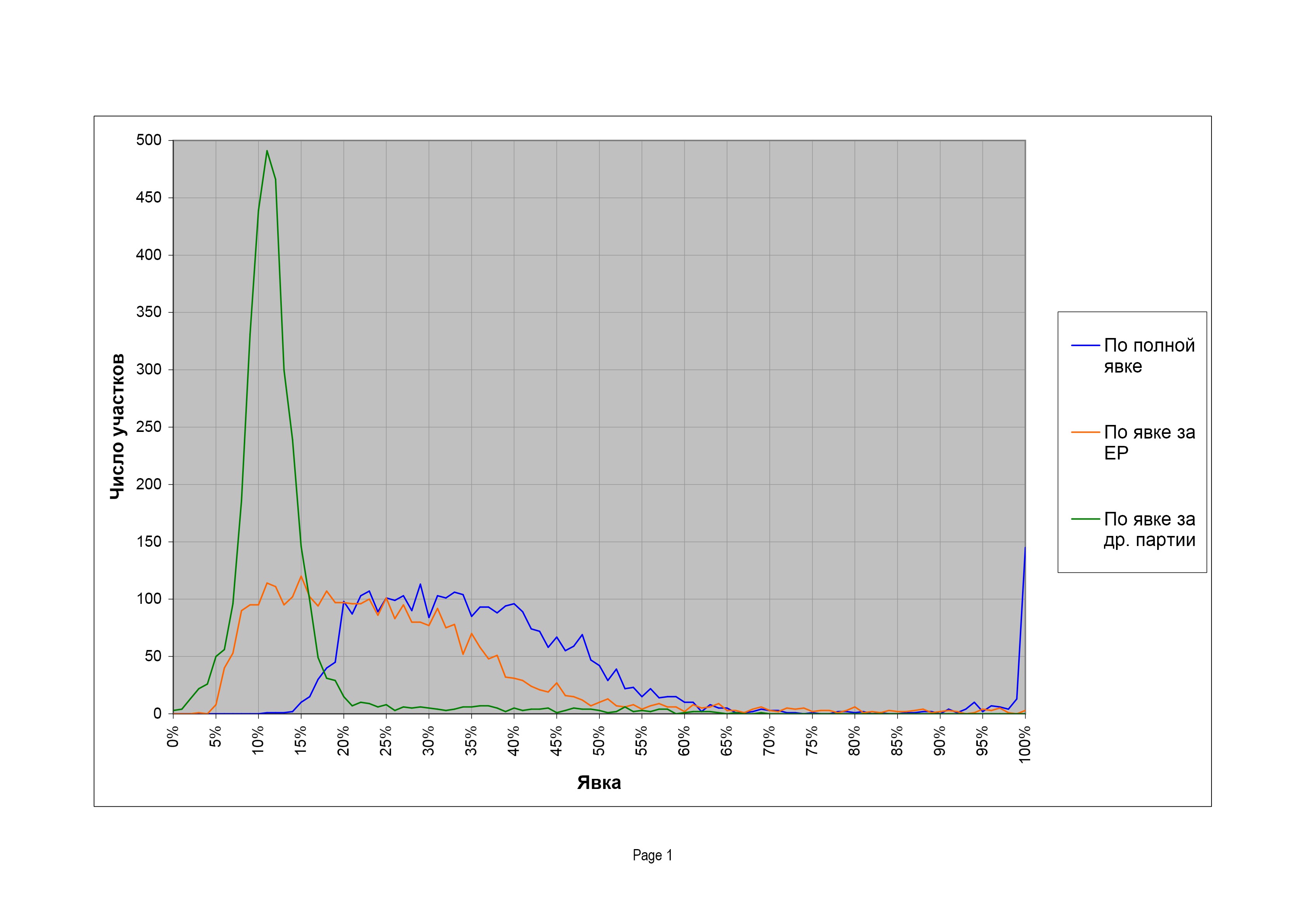
На рис. 5 приведено распределение избирательных участков по явке на думских выборах 2007 г. По оси абсцисс отложена явка в процентах, по оси ординат — количество избирательных участков, показавших такую явку (с округлением вниз, до ближайшего целого числа процентов).
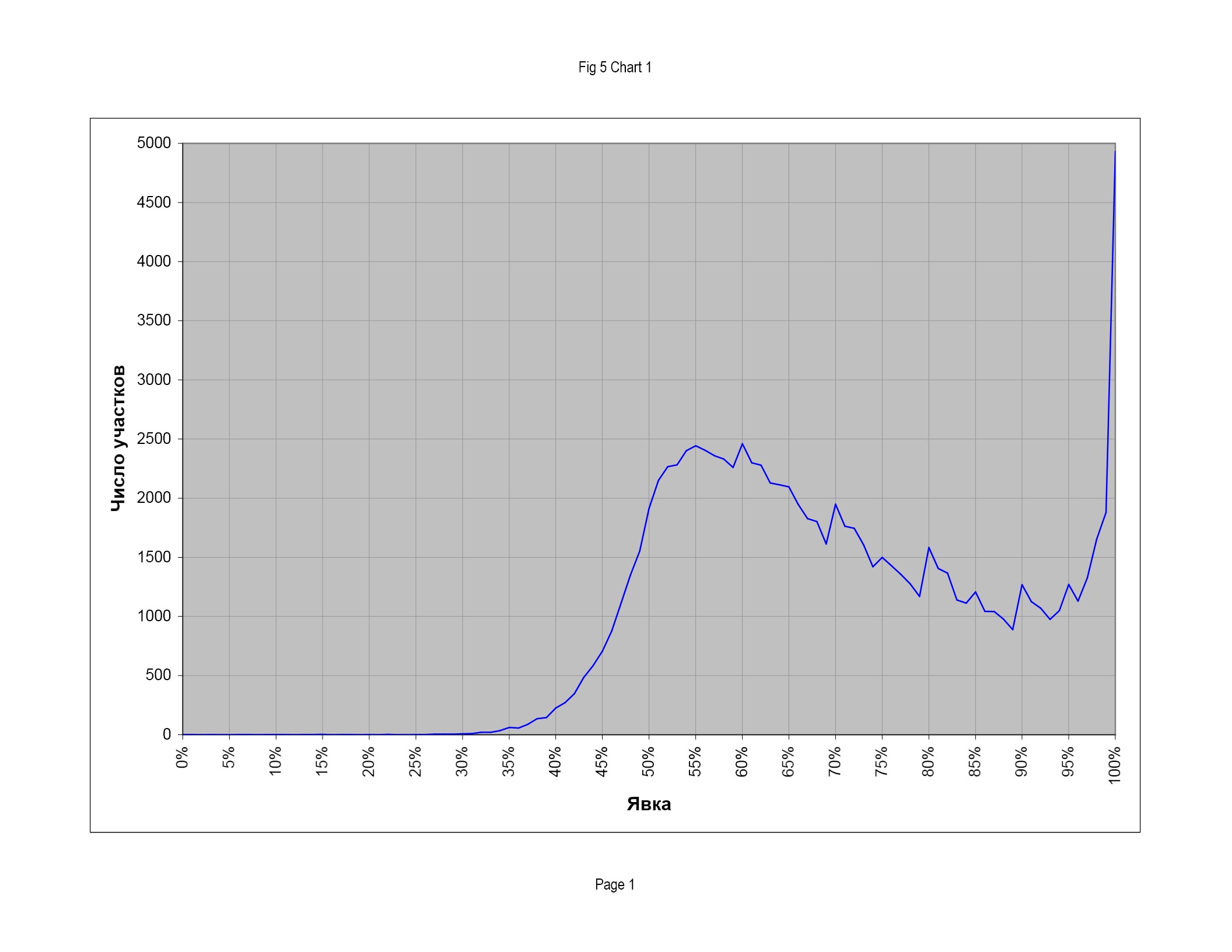
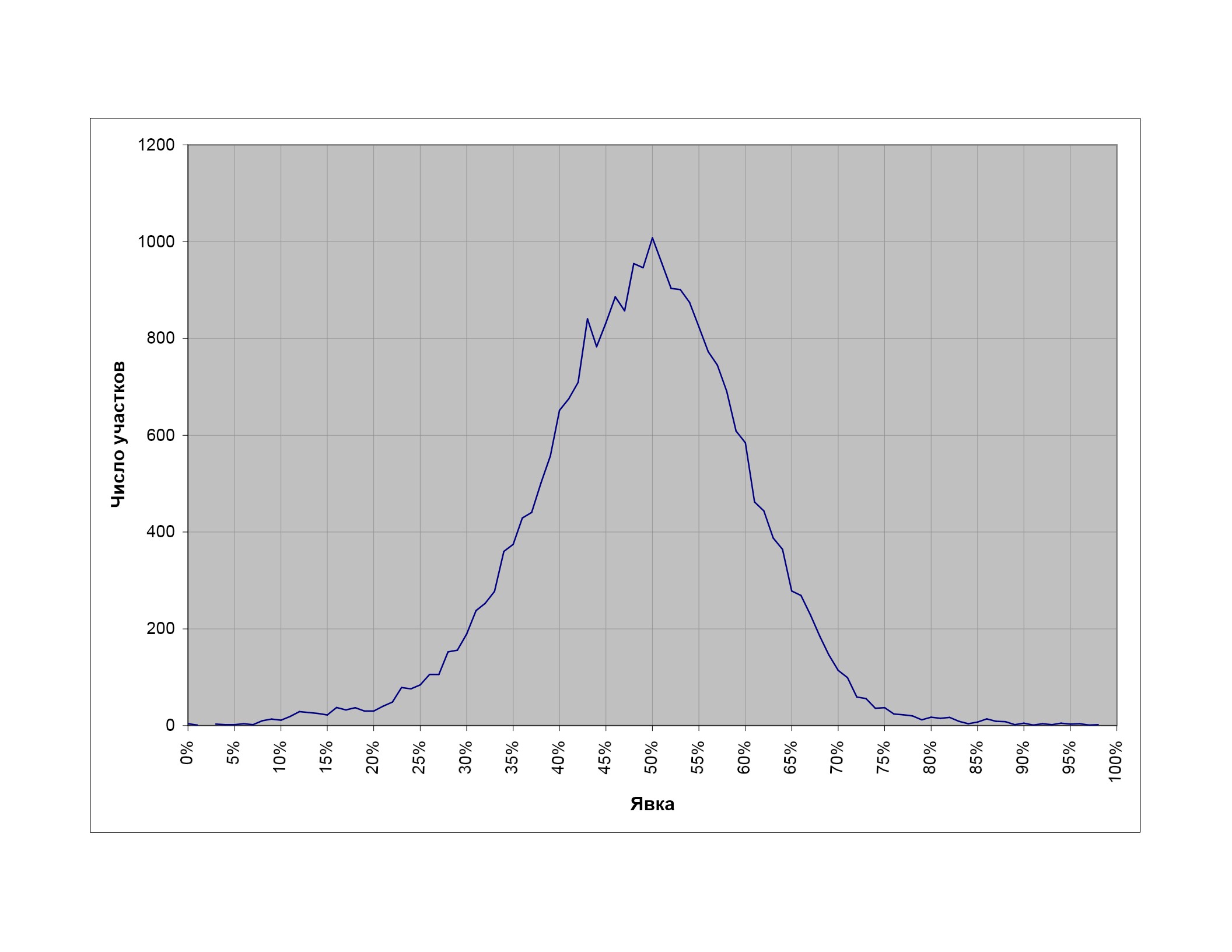
Первое, что бросается в глаза, — это необычная форма распределения в целом. Помимо основного максимума в районе 55%, распределение имеет «плечо» со стороны больших явок и резкий пик вблизи 100%. Хотя пик у 100% в основном обусловлен небольшими избирательными участками, общее число избирателей, проголосовавших на участках со 100%-ной явкой, составляет ни много ни мало 1,5 млн человек! Для объяснения столь необычной формы распределения избирательных участков по явке обычно используется тезис, что страна неоднородна и существуют территории, для которых характерны высокая явка и одновременно высокий уровень голосования за кандидатуру власти (например, сельская местность). Такая мысль проводится, например, в статье В. Чурова с соавторами (6); там же фактически признается наличие «регионов особой электоральной культуры» (читай — несвободного волеизъявления), где явка и процент голосования за властную кандидатуру могут доходить до 100%. Насколько справедлива эта аргументация — вопрос спорный; для сравнения приведем распределение избирательных участков по явке на выборах в немаленькой стране Польше (рис. 6). Здесь распределение разительно отличается от российского и гораздо больше соответствует здравому смыслу.
Однако у распределения на рис. 5 есть и вторая замечательная особенность: пики на значениях явки 60, 70, 75, 80, 85, 90, 95%. Появление таких пиков нелегко объяснить статистическими механизмами, но очень просто — человеческой психологией и стремлением показать «красивые» цифры в отчете. Это означает, что явка на выборах была предметом манипуляций и отчетным параметром, а сами результаты выборов по крайней мере частично сформированы административным воздействием. Более того, манипуляции не возникают сами по себе «снизу» — значит, было как минимум «молчаливое согласие» между теми, кто их непосредственно реализовал (на уровне избирательных участков), и теми, кто их принимал (на уровне территориальных избирательных комиссий и выше).
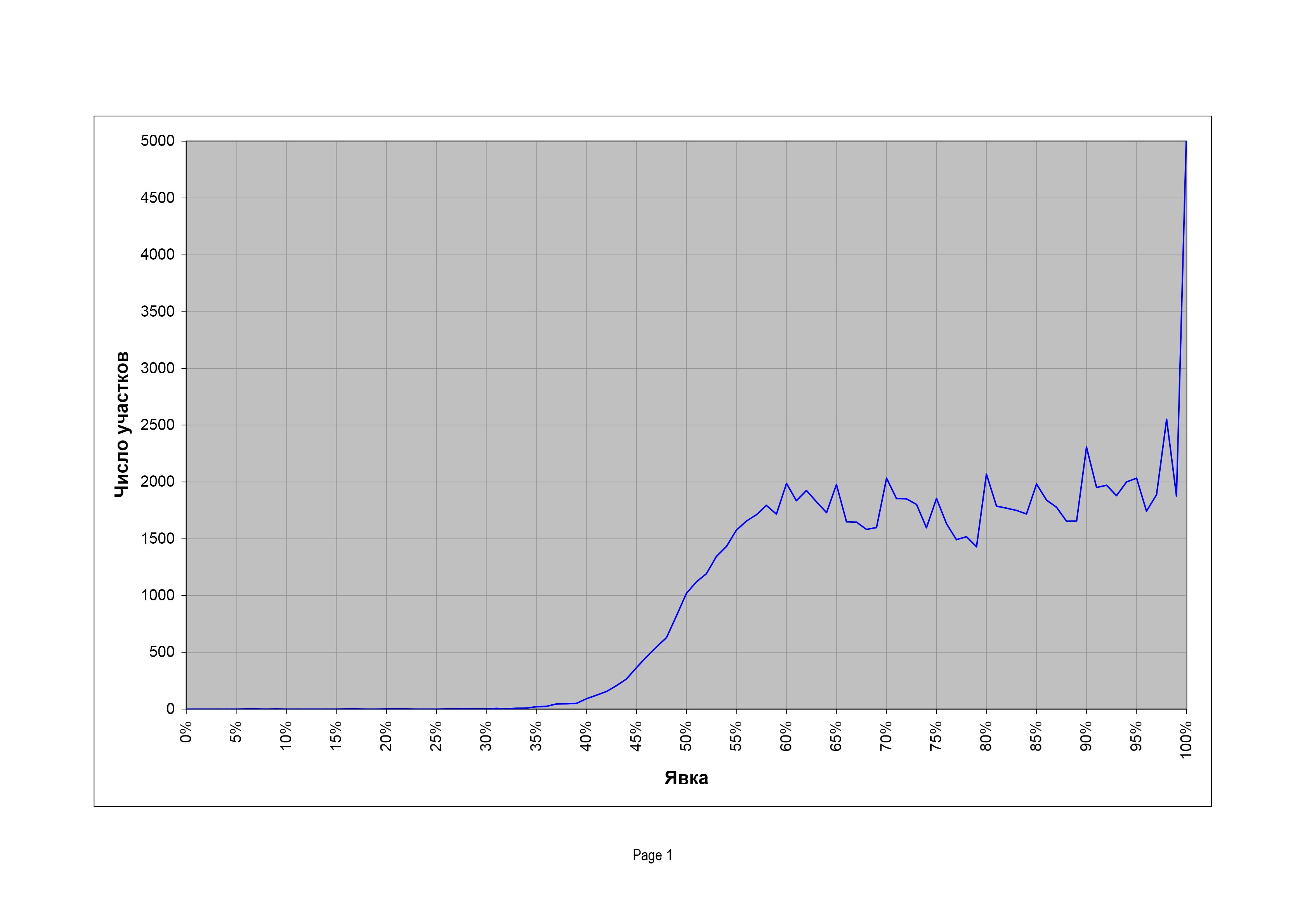
На президентских выборах 2008 г. странности распределения избирательных участков по явке только усилились (рис. 7). Начальный пик вообще пропал, а «плечо» превратилось в «плато» с мощными пиками на красивых значениях явки.
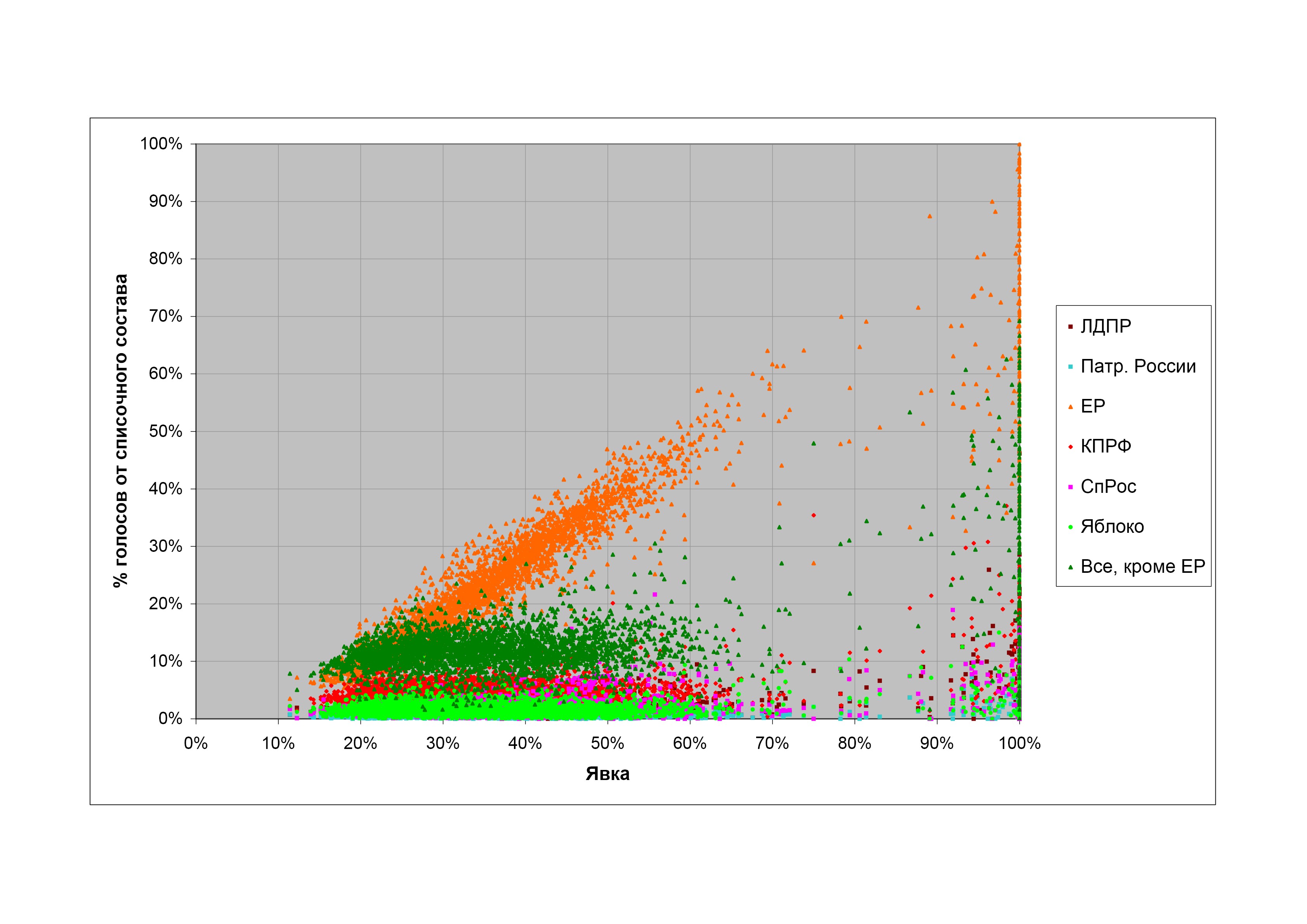
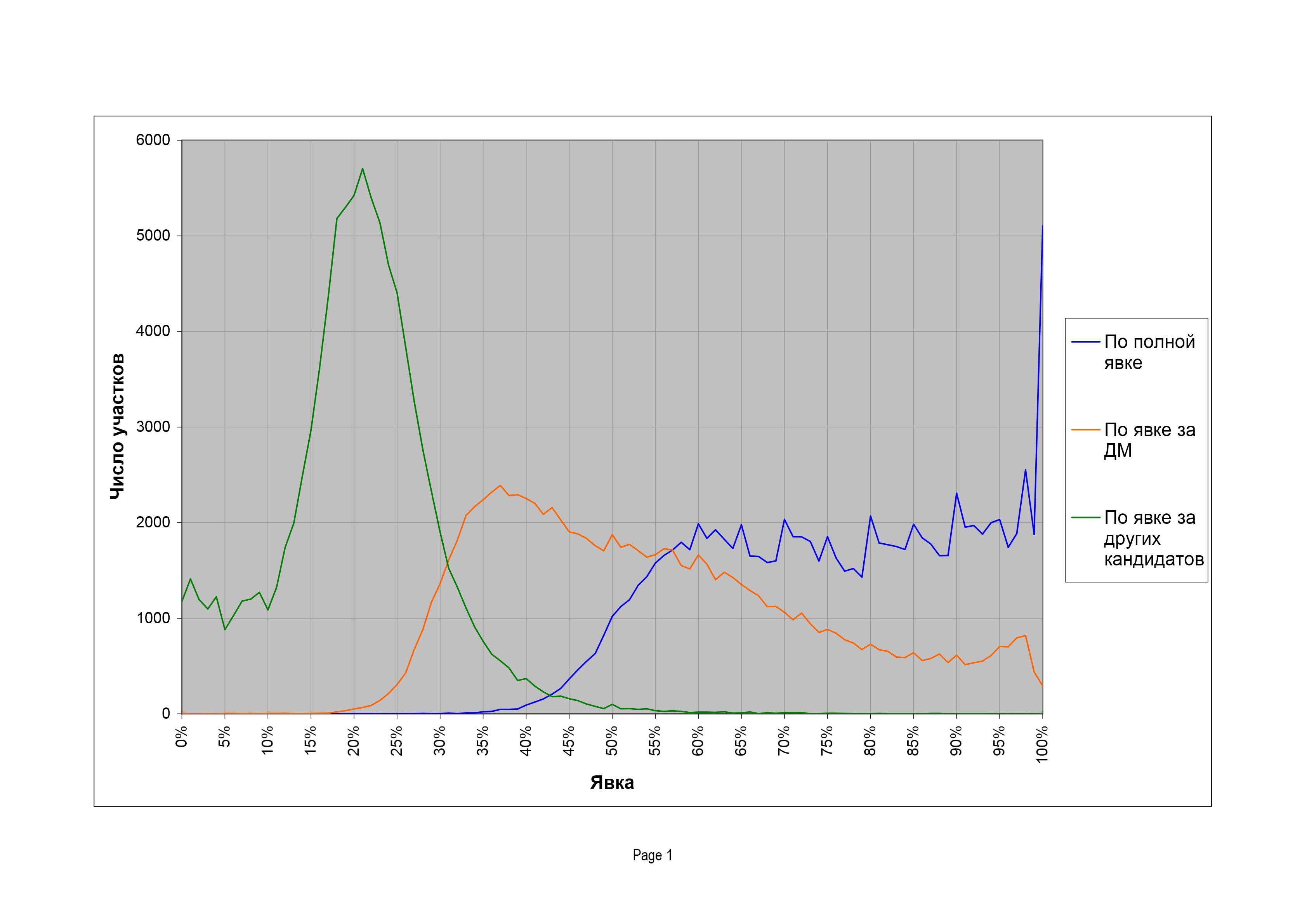
Чтобы лучше понять механизм появления подобных распределений, сделаем следующее. Разделим явку на две составляющие: явку избирателей, голосующих за кандидатуру власти, и явку избирателей, голосующих за других кандидатов, и посмотрим на распределения избирательных участков по этим двум показателям. Если вклад обеих составляющих явки в «странности» распределения по полной явке одинаков, мы можем ожидать, что распределения по обеим составляющим будут подобны, если нет — будут различия. На рис. 8 приведены соответствующие графики для президентских выборов 2008 г. (распределение по полной явке то же, что и на рис. 7).
Итак, распределение участков по явке избирателей, проголосовавших за «другие» кандидатуры, похоже на обычное нормальное распределение, за исключением добавочного «плеча» на малых явках, которое естественно связать с вышеупомянутыми «регионами особой электоральной культуры». В то же время распределение по явке избирателей, проголосовавших за Дмитрия Медведева, выглядит в высшей степени нетривиально. Возникает ощущение, что механизмы, управляющие явкой избирателей Дмитрия Медведева, с одной стороны, и избирателей других партий — с другой, радикально различаются. Подобная картина наблюдается и на других выборах. Для примера, на рис. 9 приведены аналогичные распределения для выборов 2009 г. в Мосгордуму. Картина та же: распределение по явке избирателей «остальных» партий похоже на обычное гауссово, а распределение по явке избирателей «Единой России» не похоже вообще ни на что разумное.
Зависимость статистических характеристик выборов от способа голосования
Предшествующее рассмотрение наводит на мысль, что голосование за кандидатуру власти и голосование за остальные кандидатуры управляются разными механизмами. К счастью, наша избирательная система дает возможность практически «чистой» проверки этого предположения. Эта возможность связана с комплексами автоматической обработки избирательных бюллетеней (КОИБ), которыми оборудуется часть избирательных участков. Очень удобна в этом смысле Москва, где КОИБами на выборах последних лет оснащается около 30% участков. При этом КОИБы распределяются по районам города достаточно широко и бессистемно и каждый раз по-новому, так что можно считать, что контингенты избирателей на участках с КОИБ и без них одинаковые (единственное исключение — «закрытые» участки, где КОИБы не ставятся, но в Москве на таких участках избирателей немного).
Сравним результаты голосований в Москве на участках с КОИБ и без. На рис. 10 приведены распределения избирательных участков Москвы по явке на выборах в Государственную Думу РФ 2007 г.
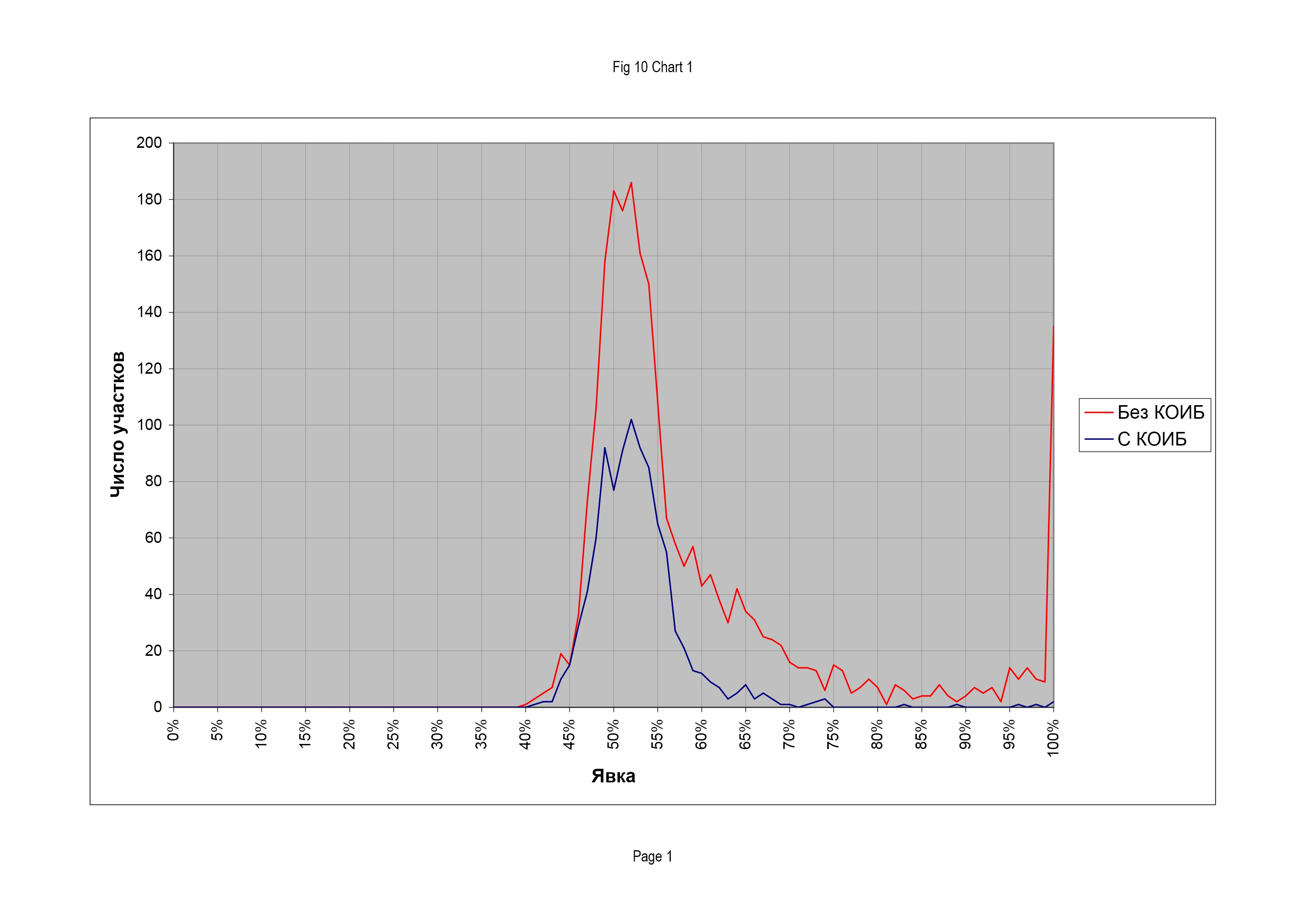
Распределения схожи между собой и похожи на нормальное (гауссово), хотя для участков без КОИБ есть «хвост» в сторону высоких явок. Однако численные результаты выборов ощутимо различаются:
|
Явка |
Доля голосов за «Единую Россию» |
|
|
Участки с КОИБ |
52,6% |
49,7% |
|
Участки без КОИБ |
56,3% |
56,1% |
Таким образом, наличие КОИБ снижает явку и почему-то долю голосов за «Единую Россию».
На президентских выборах 2008 г. различие между двумя типами участков значительно усилилось.
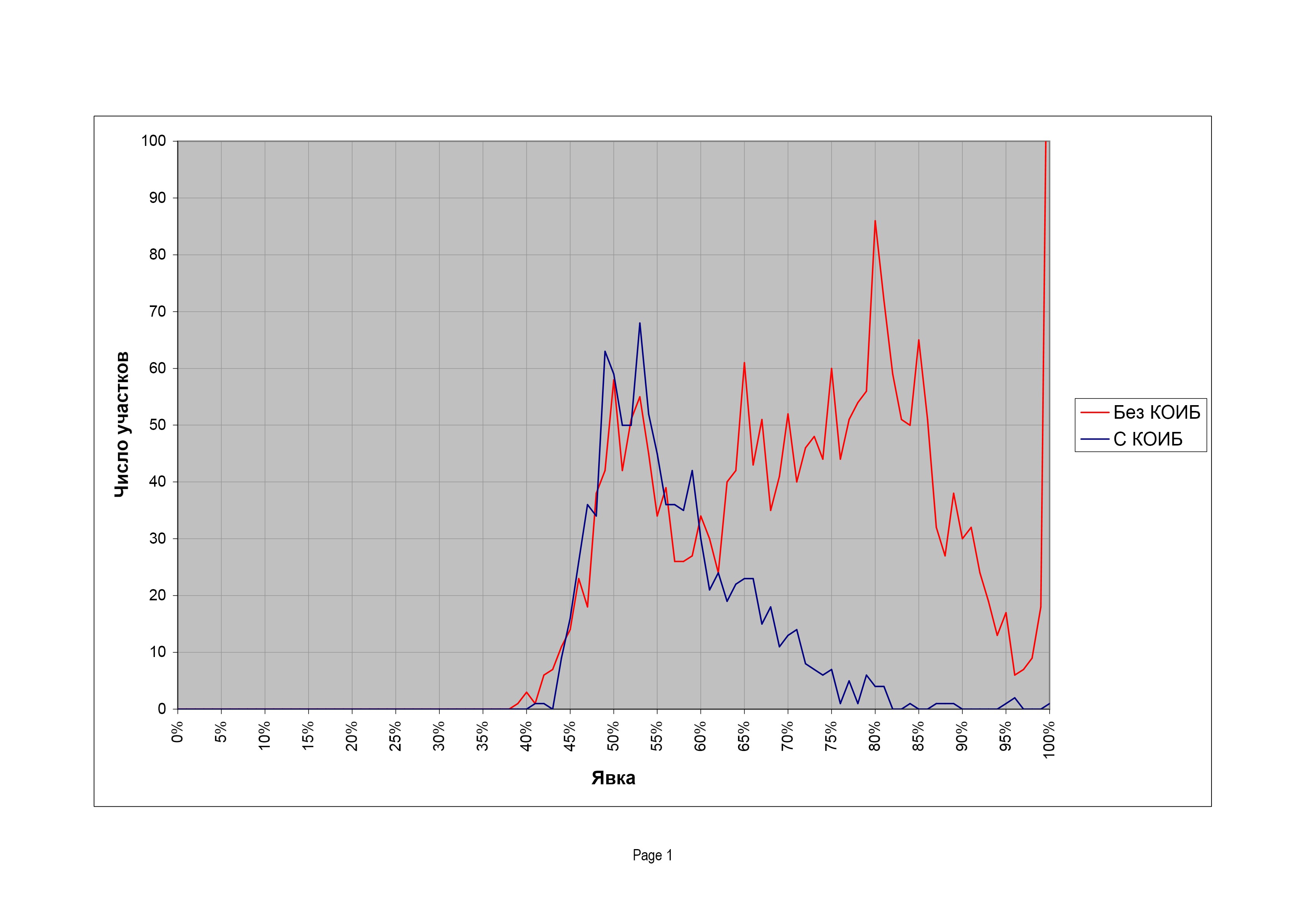
Распределения выглядят так, будто вообще относятся к разным территориям. Распределение участков с КОИБ еще сохраняет колоколообразную форму, хотя и обзавелось изрядным «хвостом» к высоким явкам. Участки же без КОИБ распределены по какому-то самобытному закону. При низких явках просматривается сходство с участками без КОИБ, но затем начинаются замечательные пики на «круглых» и «полукруглых» значениях с кульминацией на 80%-ной явке. Результаты голосования тоже различаются существенно:
|
Явка |
Доля голосов за Д.Медведева |
|
|
Участки с КОИБ |
56,1% |
65,9% |
|
Участки без КОИБ |
70,1% |
73,6% |
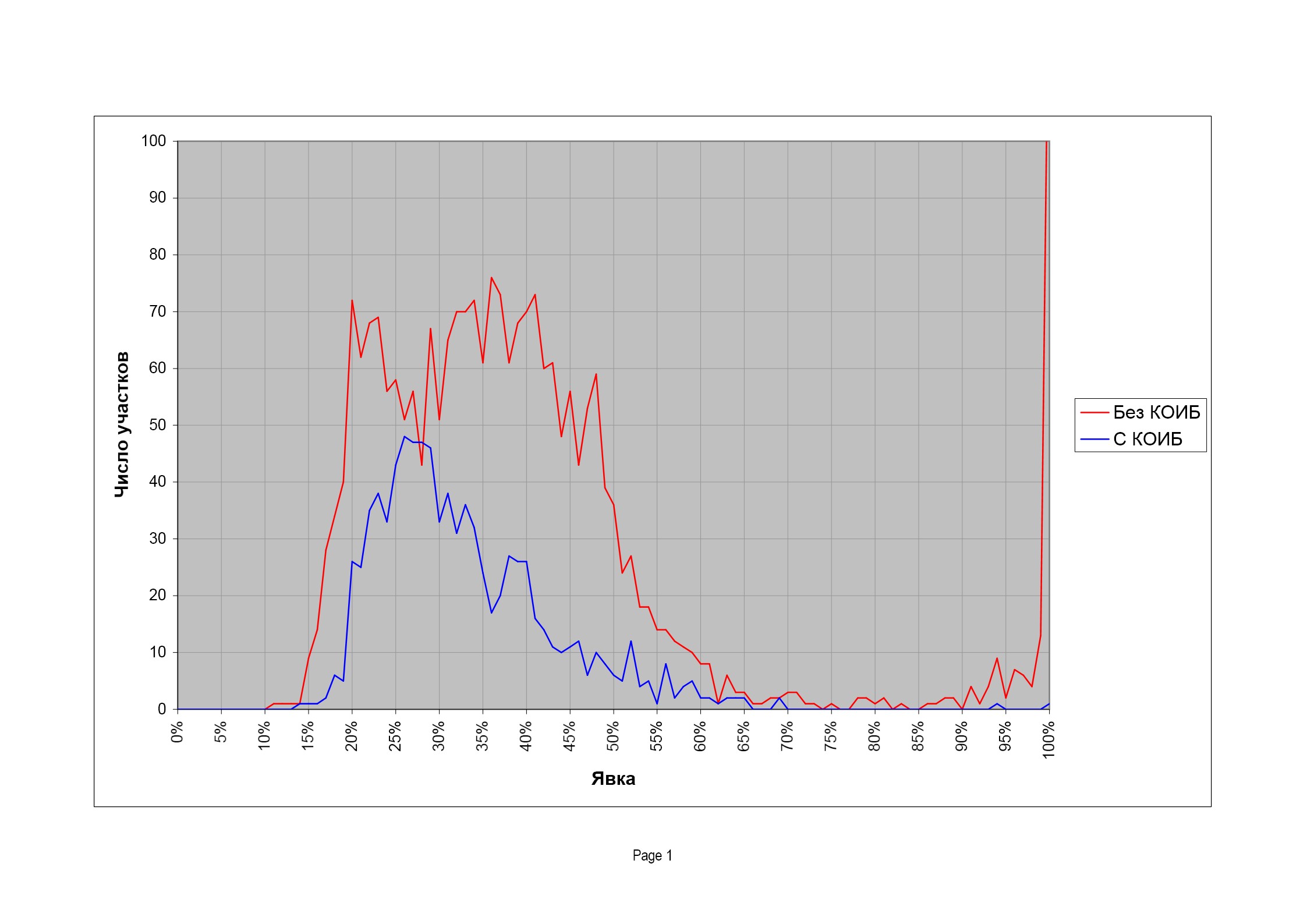
И в довершение картины — выборы в Мосгордуму в 2009 г. Распределения участков с КОИБ и без опять радикально различаются. Результаты голосования тоже различаются, но не так сильно, как на предыдущих выборах. Такое ощущение, что КОИБы «приручили»:
|
Явка |
Доля голосов за «Единую Россию» |
|
|
Участки с КОИБ |
33,2% |
67,4% |
|
Участки без КОИБ |
36,1% |
67,5% |
Количественная оценка аномалий
Из предыдущих двух глав видно, что с точки зрения статистики выборов избиратели кандидатуры власти и избиратели всех остальных кандидатов на российских выборах последних лет ведут себя совершенно по-разному: приходят на избирательные участки не по закону нормального распределения, а по своим особым законам, имеют особую склонность к голосованию на участках с высокой явкой, по-разному голосуют на участках с автоматическими сканерами бюллетеней и без них.
Вообще говоря, науке известны подобные явления. Самый известный пример — жидкий гелий, ведущий себя при температуре ниже температуры фазового перехода как смесь двух компонент — нормальной и сверхтекучей, которая отличается совершенно экзотическими свойствами: способна протекать через мельчайшие щели, утекать из сосуда по капиллярной пленке и т.п. Избиратели кандидатур власти своими экзотическими привычками во многих отношениях напоминают сверхтекучую компоненту жидкого гелия: например, склонность голосовать при высокой явке является несомненным аналогом бозе-конденсации. Этот вопрос несомненно заслуживает дополнительного изучения, хотя и выходит за рамки данной статьи.
Если же отбросить фантастические гипотезы, самым разумным объяснением такого поведения избирателей, голосующих за кандидатуры власти, представляется то, что часть голосов за такие кандидатуры получена в результате манипуляций — от административного давления вроде «не будете голосовать как надо — отключим газ (не привезем дров, закроем магазин, уволим по статье)» до вбросов и приписок. Тогда возникает вопрос: можно ли, опираясь только на статистические данные, определить, чему равна эта часть голосов (назовем ее аномальной составляющей голосов за кандидатуру власти, в противоположность нормальной, полученной в результате свободного волеизъявления граждан)?
Понятно, что в общем случае задача неразрешима: если статистические данные выборов подделаны полностью и не имеют никакого отношения к реальным результатам голосования, восстановить реальные результаты невозможно. С другой стороны, некоторые признаки (постоянство долей голосов за «прочие» партии при изменении явки на рис. 1-4, подобие распределений участков при низких явках на рис. 11) показывают, что в официальных результатах голосования есть реальная составляющая. Попробуем определить «нормальную» и «аномальную» части голосов за кандидатуры власти, используя эти реальные данные как эталон.
В связи с этим можно высказать несколько наводящих соображений. Мы видели, что голосование за разные партии существенно зависит от явки. Кроме того, очевидно, что простое вбрасывание/приписывание голосов за кандидатуру власти (самый простой вид манипуляции) на конкретном избирательном участке приводит к смещению этого избирательного участка вместе со всеми его данными (и реальными, и фальсифицированными) в сторону более высоких явок. В результате на низких явках должны оставаться участки с нефальсифицированными данными. Далее, можно предполагать, что голоса вбрасываются только за кандидатуру власти, а у остальных кандидатур они остаются неизменными либо, при более злостных манипуляциях, отбираются. Поэтому можно попробовать использовать в качестве эталона данные участков с невысокой явкой, а также данные голосований за «прочие» кандидатуры.
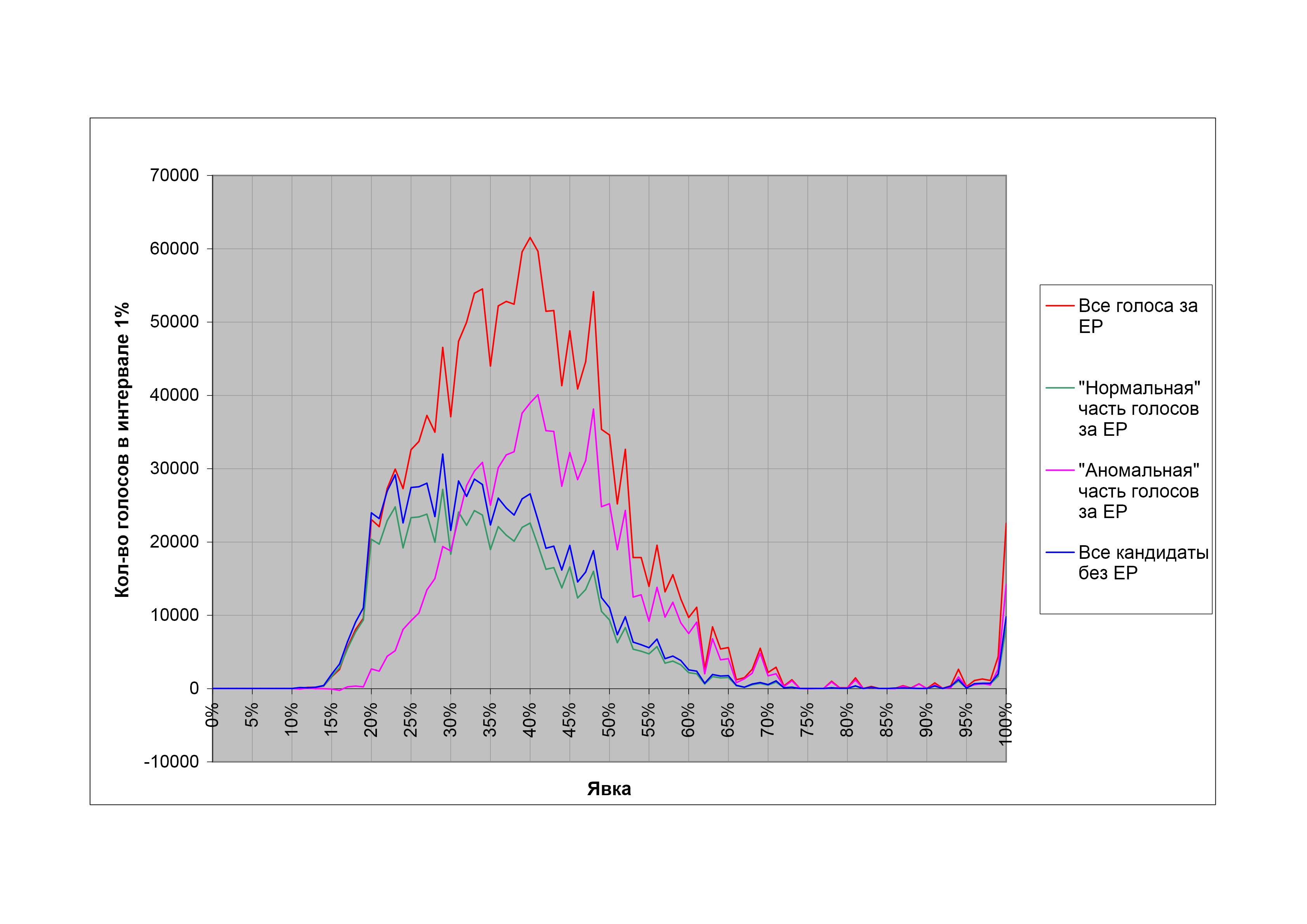
В соответствии с этими соображениями исследуем распределения голосов за разные кандидатуры в зависимости от явки на избирательном участке. На рис. 13 показано такое распределение для думских выборов 2007 г. По оси абсцисс отложена явка в процентах, по оси ординат — суммарное количество голосов за различные кандидатуры на участках с данной явкой (явка округляется вниз, до ближайшего целого, т.е. голоса суммируются по интервалам в 1%). Дополнительно показано распределение суммы голосов за все партии, кроме «Единой России».
Может ли российский электорат состоять из двух частей, настолько отличающихся по поведению, как избиратели кандидатов от власти и прочих кандидатов? Вообще говоря, науке известны подобные явления. Самый известный пример -жидкий гелий, ведущий себя при температуре ниже температуры фазового перехода как смесь двух компонент — нормальной и сверхтекучей, которая отличается совершенно экзотическими свойствами: способна протекать без трения через мельчайшие щели, утекать из сосуда по капиллярной пленке и т.п. Избиратели кандидатур власти своими экзотическими привычками во многих отношениях напоминают сверхтекучую компоненту жидкого гелия — например, склонность голосовать при высокой явке является несомненным аналогом бозе-конденсации. Этот вопрос несомненно заслуживает дополнительного изучения.
Из рис. 13 видно, что распределения по явке голосов за все партии, кроме «Единой России», с хорошей точностью подобны (это подтверждается, если нормировать их на суммарное распределение голосов «прочих» партий: полученные нормированные распределения практически постоянны в широком диапазоне явок), и только распределение голосов за ЕР ведет себя по-другому. При этом при невысоких явках (где-то до 55%) оно также подобно распределению голосов за «прочие» партии и лишь затем начинает отклоняться вверх от общей тенденции. Естественно предположить, что это отклонение и представляет собой «аномальную» часть голосов за ЕР, а «нормальная» часть голосов за ЕР должна быть распределена подобно распределениям голосов за все остальные партии. Сформулируем это предположение математически. Представим распределение голосов за ЕР в виде: (все голоса за ЕР) = С * (голоса за все партии без ЕР) + (аномальная часть голосов за ЕР), где С — подгоночный коэффициент, подбираемый так, чтобы при невысоких явках (где, как говорилось выше, должны оставаться только «честные» участки) аномальная часть была по возможности близка к нулю. Эмпирическим путем выясняется, что такое представление действительно возможно.
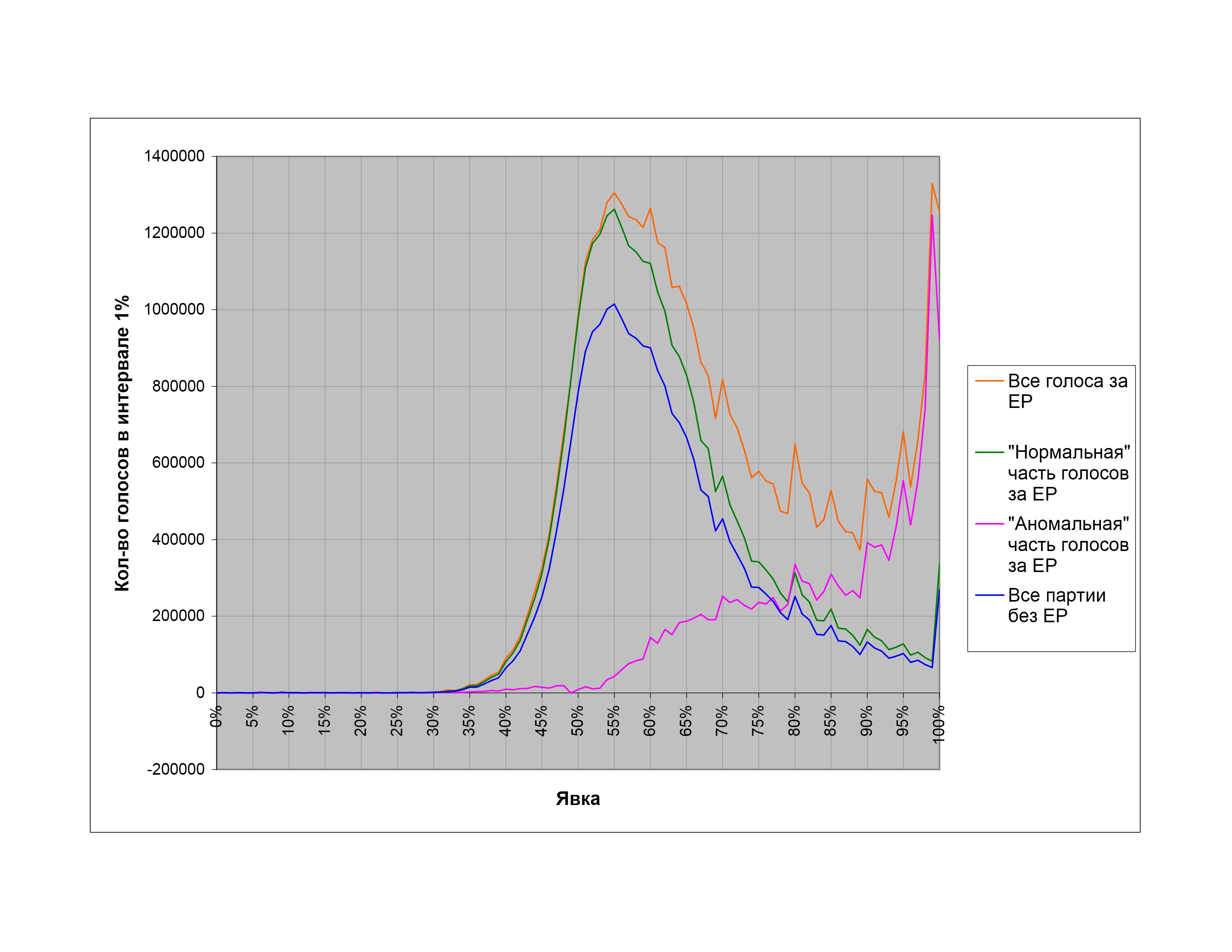
Видно, что голоса за ЕР действительно удается разделить так, что «нормальная» часть подобна распределению голосов за другие партии, а «аномальная» часть близка к нулю ниже определенного значения явки (примерно 52%). Выше этой пороговой явки аномальная часть начинает резко и устойчиво расти. Понятно, что выбор подгоночного коэффициента С сопряжен с некоторым произволом; в данном случае он выбран так, чтобы аномальная часть была везде положительна.
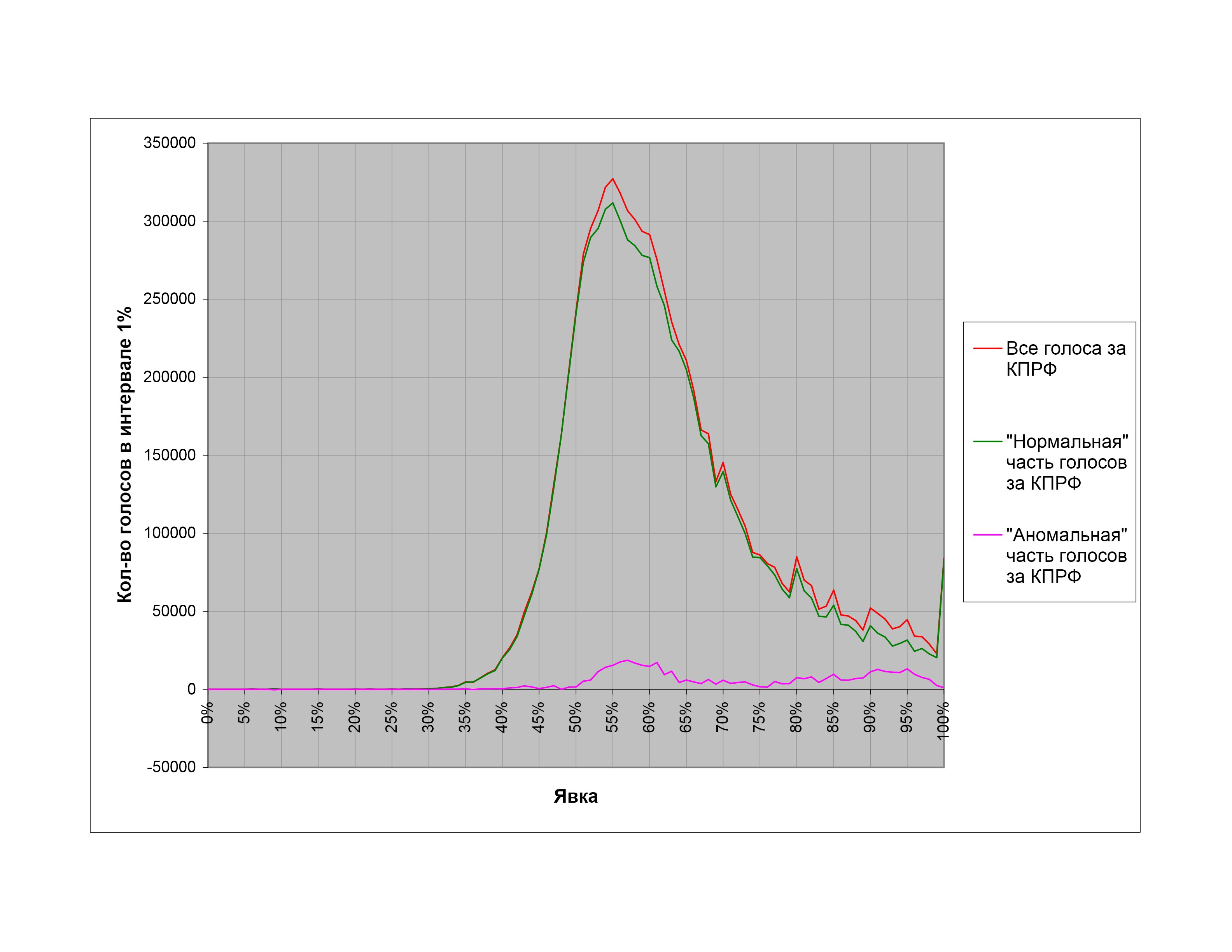
Для контроля методики полезно попытаться разделить на «нормальную» и «аномальную» части голоса какой-либо другой партии, которую мы не подозреваем в применении административного ресурса. На рис. 15 приведено такое разделение для голосов за КПРФ на тех же думских выборах 2007 г. Видно, что «аномальная» составляющая голосов, если и присутствует, интегрально значительно меньше, чем у ЕР, что задним числом оправдывает наш подход.
Теперь, имея разделение голосов за «Единую Россию» на «нормальную» и «аномальную» части, можно задаться вопросом: какими были бы результаты думских выборов 2007 года в отсутствие «аномального» вклада в голосование за ЕР? Для показанного выше разделения количество «нормальных» голосов за «Единую Россию» составляет 30,7 млн, «аномальных» — 13,8 млн. Отбросив «аномальные» голоса за ЕР, получим следующие гипотетические результаты выборов:
|
Официально |
С коррекцией |
|
|
Явка |
63,7% |
51,0% |
|
КПРФ |
11,6% |
14,5% |
|
ЛДПР |
8,1% |
10,1% |
|
СпРос |
7,7% |
9,7% |
|
ЕР |
64,3% |
55,7% |
Таким образом, «Единая Россия» при гипотетическом «скорректированном» голосовании по-прежнему имела бы в парламенте большинство, но уже не конституционное. Естественно, скорректированные результаты зависят от выбора подгоночного коэффициента в разделении на «нормальную» и «аномальную» части, однако варьирование этого коэффициента в разумных пределах, при которых «аномальная» часть голосов на рис. 13 остается близкой к нулю при явках ниже порога, изменяет количество мандатов ЕР в Думе не более чем на ±1%, так что оценку можно считать корректной.
Таким же образом можно разделить на «нормальную» и «аномальную» части голо са за Дмитрия Медведева на президентских выборах 2008 г. (рис. 16):
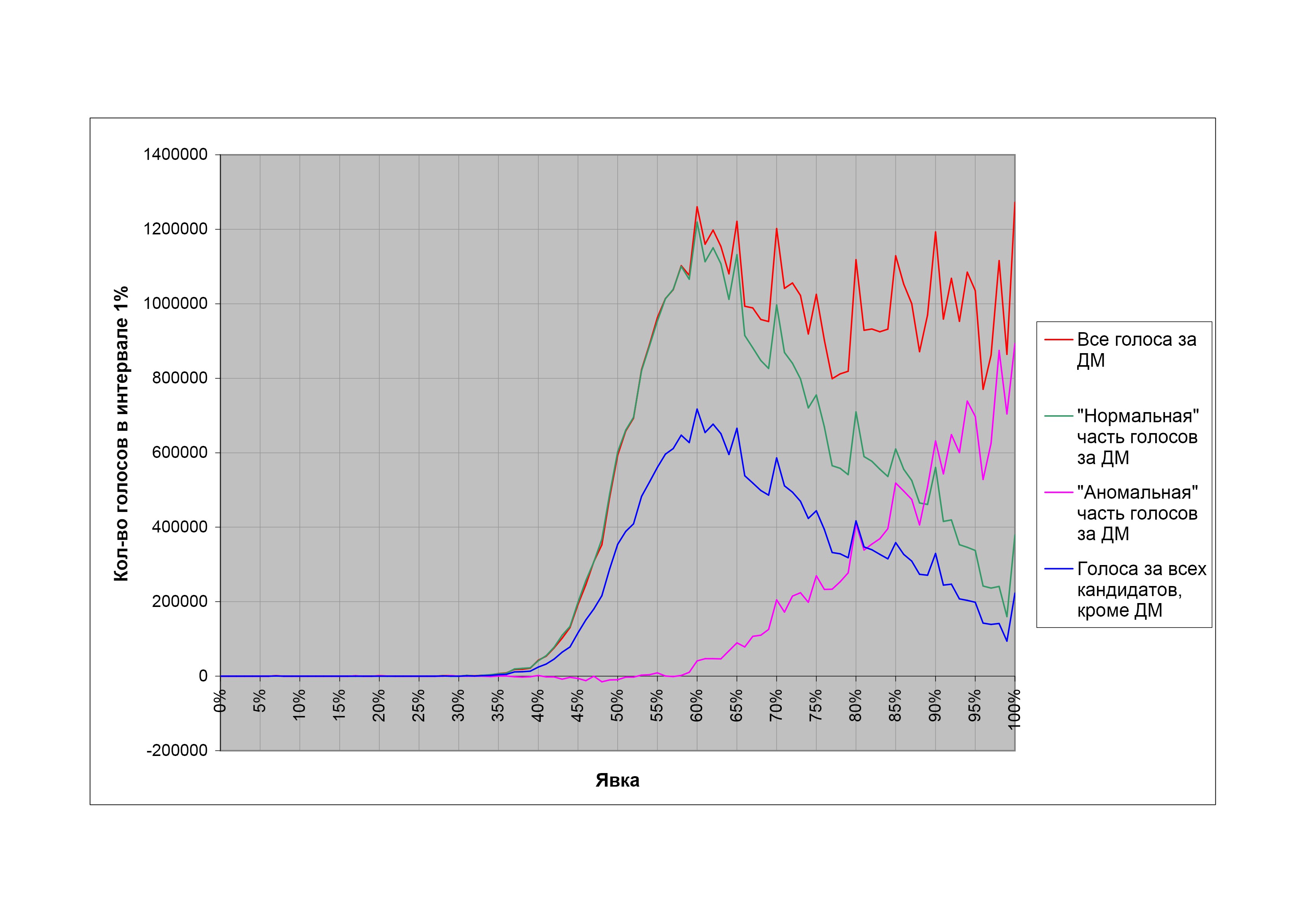
Такое разделение дает 37,8 млн «нормальных» и 14,8 млн «аномальных» голосов за Медведева; гипотетические скорректированные результаты выборов выглядят следующим образом:
|
Официально |
С коррекцией |
|
|
Явка |
69,7% |
55,9% |
|
Богданов |
1,3% |
1,6% |
|
Жириновский |
9,35% |
11,65% |
|
Зюганов |
17,7% |
22,1% |
|
Медведев |
70,28% |
62,96% |
|
Недействительные бюллетени |
1,36% |
1,69% |
Наконец, разделим на «нормальную» и «аномальную» части голоса за список «Единой России» на недавних выборах в Мосгордуму:
Скорректированные итоги выборов выглядят следующим образом:
|
Официально |
С коррекцией |
|
| Явка |
35,3% |
22,0% |
| ЛДПР |
6,13% |
9,82% |
| Патриоты России |
1,81% |
2,90% |
| Единая Россия |
66,24% |
45,95% |
| КПРФ |
13,30% |
21,29% |
| Справедливая Россия |
5,33% |
8,54% |
| Яблоко |
4,71% |
7,54% |
| Недействительные бюллетени |
2,48% |
3,97% |
Можно отметить, что скорректированные оценки явки и процента голосов за «Единую Россию» лучше согласуются с числами, которые дают различные наблюдатели, чем официальные результаты.
Заключение
При всех недостатках современной российской выборной системы у нее есть несомненное достоинство — открытость данных. Надеюсь, эта статья и изложенные в ней подходы привлекут к анализу выборной статистики общественный интерес.
Автор хотел бы выразить благодарность всем читателям блога podmoskovnik.livejournal.com за многочисленные плодотворные обсуждения, а также А.Е. Любареву и А.Ю. Бузину, посвятившим автора-дилетанта в историю вопроса.
Литература
2. Собянин А.А., Суховольский В.Г. Демократия, ограниченная фальсификациями: Выборы и референдумы в России в 1991-1993 гг. М., 1995 www.hrights.ru/text/sob/
3. M. Myagkov, P. Ordeshook, D. Shakin, The Forensics of Election Fraud: Russia and Ukraine, Cambridge University Press, 2008; см. также http://vote.caltech.edu/drupal/files/working_paper/vtp_wp63.pdf
4. Mebane, Walter R., Jr., and Kirill Kalinin 2009. «Comparative Election Fraud Detection». www.umich.edu/~wmebane/apsa09.pdf
5. Бузин А.Ю., Любарев А.Е. Преступление без наказания. Административные технологии федеральных выборов 2007-2008 годов. Группа Компаний «Никколо М», Панорама, 2008
6. Чуров В.Е., Арлазаров В.Л., Соловьев А.В. Итоги выборов. Анализ электоральных предпочтений. www.cikrf.ru/newsite/illuziya/itogi_160908.jsp
7. Шень А. Выборы и статистика: казус «Единой России» (2009). http://alexander.shen.free.fr/elections.pdf Некоторые массивы выборных данных, использованные в статье, размещены на сайте Независимого института выборов, на странице www.vibory.ru/elects/UIK.htm
С автором статьи можно связаться по электронной почте [email protected] или через его блог podmoskovnik.livejournal.com
P.S.
Когда верстался номер, пришло сообщение о том, что на участке № 192 в Хамовниках, где голосовал глава «Яблока» Сергей Митрохин с семьей и где по официальным результатам не было подано ни одного голоса за «Яблоко», в соответствии с решением Хамовнического суда был произведен пересчет бюллетеней. В результате пересчета среди 87 бюллетеней, ранее засчитанных КПРФ, было найдено 16 бюллетеней за «Яблоко», 3 бюллетеня за ЛДПР и 1 за «Патриотов России». Среди 29 бюллетеней за «Справедливую Россию» было найдено 2 недействительных. Среди 904 бюллетеня за «Единую Россию» неправильно подсчитанных обнаружено не было.
Таким образом, среди 116 бюллетеней, поданных за оппозиционные партии, оказалось 22 неверно учтенных, а среди 904 бюллетеней за ЕР — ни одного. Нетрудно подсчитать, что вероятность такого события, в предположении, что при изначальном подсчете все бюллетени учитывались одинаково тщательно и пересчет выполнен точно, составляет (116!*998!)/(94!*1020!), т.е. примерно 2,5 на 10 в минус 22-й степени. Российская избирательная система еще раз подтвердила, что для нее нет непреодолимых препятствий в теории вероятностей.
Сергей Шпилькин, независимый исследователь
См. также Выборы-2011
Мне совершенно непонятен смысл графиков на рисунках 8 и 9. Как это — «явка избирателей, проголосовавших за Медведева»? Если человек проголосовал, то он соответственно явился, а если не явился — откуда известно, за кого бы он проголосовал?
По оси Х процент проголосовавших за Медведева от общего числа зарегестрированных избирателей на участке, по оси Y число участков, где подобное произошло.
Хотел высказаться на счет «правильных» всплесков на значениях явки 60, 70, 75, 80, 85, 90, 95% . По изображениям видно, что графики строятся поточечно,а затем эти точки для наглядности просто соединяются программой. На один квадратик (на5%) приходится 5 точек, крайние из которых привязаны к узлам решетки (это те самые 60, 70, 75, 80, 85, 90, 95%).
Вывод: всплески, конечно, есть, но вряд ли их пики в действительности (а не на графике) выпадают на такие «правильные» значения.
P.S. статья очень познавательная и интересная, но и навязывание одной точки зрения (на мой взгляд) велико)
Насколько я понимаю, данные по явке округляются до целого значения. Поэтому пики на графиках соответсвуют существующим цифрам независимо от способа построения кривой.
Не очень понял суть претензии, но вот фрагмент таблицы данных, по которой построен график для 2008 года. По-моему, пики видны отчетливо.
Явка округляется вниз до целых процентов, т.е., например, в группу 0.71 попадают участки с явкой от 0.71000 до 0.71999
Явка Кол-во участков
0.65 1977
0.66 1650
0.67 1647
0.68 1582
0.69 1598
0.70 2034
0.71 1854
0.72 1852
0.73 1802
0.74 1598
0.75 1854
0.76 1632
0.77 1493
0.78 1519
0.79 1429
0.80 2069
0.81 1787
0.82 1770
0.83 1749
0.84 1718
0.85 1983
0.86 1842
0.87 1777
0.88 1655
0.89 1657
0.90 2306
0.91 1952
0.92 1971
0.93 1880
0.94 2000
0.95 2033
0.96 1743
0.97 1887
0.98 2552
0.99 1878
1.00 5105
Расскажите в какой проге Вы обрабатываете результаты? Можно такой анализ делать в Экселе, но нужен макрос для сортировки и выборки.
Кстати на будущих выборах в России нужно будет обратить особое внимание на кол-во испорченных и неучтённых бюллетеней. Думаю у вас их будет не мало и, к тому же, их кол-во также будет подгоняться и завышаться искусственно чтобы уменьшить число голосов конкурентов ЕдРа.
Ну и общефилософские мысли. Хорошо бы, чтобы эти и будущие результаты стали известны и оппозиционным силам и лидерам (Яблоко, Немцов и Ко.) и зарубежным независимым наблюдателям. Ведь они имеют очень основательную достоверность и весомую доказательность!
Что под рукой — Excel + VBA.
По поводу методики. trim_c из ЖЖ, количество участков нормировал на число избирателей в них, думаю это правильно. Тем самым по оси ординат получаем не абстрактные участки с разным «электоральным весом», а фактически реальные голоса людей.
Кажется, что выявляя эффект «круглых цыфр», группировать участки по явке лучше бы не «вниз», а «вверх» т.к. думается, что легче и «лучше» вбросить бюллетени, чем их как-то изымать или делать недействительными. Хотя на сколько скажется такой эффект, сказать трудно. Может быть для начала попробовать на старых, уже Вами просчитанных выборах.
PS
Что касается укр. выборов 2010 года, рекомендую прочитать (хоть и на украинском, но думаю будет понятно. Начало можно опустить) статью: http://texty.org.ua/pg/article/devrand/read/14798
Цитата:
Зверніть увагу на те, що графік Тимошенко (которая — борец за демократию, Aurum) з якогось моменту перетинає графік Януковича, хоча такого бути не повинно. Таке аномальне збільшення показників Тимошенко може непрямо свідчити, що загалом по країні адмінресурс прем’єрки виявився довшим, ніж адмінресурс лідера ПР (Партия Регионов — Янук.).
http://texty.org.ua/mod/file/thumbnail.php?file_guid=29110&size=large
1. Не вполне согласен. Если говорить о круглых явках, «элементарным событием» (и событием преступления) все-таки является факт подгонки явки на участке, и степень серьезности этого события не снижается оттого, что участок небольшой. При более подробном анализе стоит, конечно, анализировать и численность таких участков. Для Москвы-2008 отбрасывал мелкие участки — эффект сохраняется полностью.
2. Психологически 70.1% в отчете выглядит как 70%, а 69.9% — как 69% (эффект, известный по ценам в супермаркетах). Поэтому округление явки вниз как раз оправданно. Пробовали группировать по правилам округления — эффект просматривается хуже.
3. Почитаю, спасибо. Некоторые тексты этого автора я видел.
>1)…
Что касается эффекта «круглых чисел», то конечно для нагядности нужно дрять участки без их веса. А вот если считать объем фальсификаций и оценивать честность выборов в целом, тут нужно учитывать электоральный вес :)
>2)…
От психологии объективность подсчёта не зависит. В принципе всё равно в какую сторону округлять числа если их много. Эксель округляет вниз по дефолту — это его право. Но если есть несимметричность когда легче вбросить бллетени, чем их изъять (зачем махинаторам снижать явку, за которую «их гладят по головке»?), то метод округления может «дать эффект».
Уровни вложенности кончились, отвечаю здесь.
1. При количественной оценке (рис 13 — 16) учитывается именно численность избирателей.
2. Явку, конечно, никогда не занижают, но повышают ее именно до круглых значений.
Все здесь прекрасно, а гуманитарные мудозвоны в комментах просто восхитительны!
Очень полезная статья, хотелось-бы только ещё более подробного анализа возможных злоупотреблений и соответственно хоть какого-либо противодействия им при голосовании на участках с комплексами автоматической обработки избирательных бюллетеней (КОИБ).
На скорую руку посмотрел результаты выборов 4.12.2011, картинка в точности повторяет Рис.1 из этой статьи!
Зависимость результатов голосования от явки избирателей 4.12.2011
Только лучше откладывать по оси ординат долю от числа зарегистрированных избирателей, а не от проголосовавших. Тогда нижние будут горизонтальны. Анализ на скорую руку, пока по ТИК: podmoskovnik.livejournal.com
Спасибо за совет. Я в эту проблематику глубоко никогда не вникал и в во множестве показателей просто заблудился.
с нетерпением ждем обновления информации.
Мой вариант на скорую руку по промежуточным данным избиркома (95% обработано).
http://imageshack.us/photo/my-images/683/elections2011.png/
Это по ТИКам, как я понимаю?
Спасибо. Т.е. картина та же самая — активности избирателей всех партий распределены более-менее по Гауссу, а избирателей ЕР — как попало.
Данные по верхнему уровню сводной таблицы
http://www.vybory.izbirkom.ru/region/region/izbirkom?action=show&root=1&tvd=100100028713304&vrn=100100028713299®ion=0&global=1&sub_region=0&prver=0&pronetvd=null&vibid=100100028713304&type=233
Не, не катит. Откуда взялись пики по голосам за другие партии при „круглой” явке? Рис. 13, например.
1) Согласно вашей гипотезе, „круглые” цифры явки — результат приписки. Логично: если б дело обстояло иначе — например, если бы начальство просто тупо гнало бы на выборы всех подряд — „красивые” значения не получились бы: вряд ли по достижению 70%, к примеру, вдруг был бы объявлен отбой, и остальных пришедших завернули бы (заранее тут не подгадаешь). Так может выйти, только если происходит целенаправленный вброс: тут уже можно подсчитать, сколько надо добавить до нужной „круглой” отметки.
2) Но согласно вашему другому постулату, все вброшенные бюллетени были в поддержку ЕР/Медведева.
В этом случае никаких пиков по числу поданых голосов у оппозиционных партий при „круглых” значениях явки быть не может. Ведь сама „круглость” образовалась за счёт вброса, а вброс шёл толькоза ЕР. На графике явки пик в районе 60 и 70% — будет, на графике голосов, поданых за ЕР — тем более будет, а на графиках голосов, поданых за остальные партии — нет. А у вас — есть. Странно…
Получается, что мухлёж шёл не только в пользу ЕР, но и остальных партий тоже! Как это возможно? Даже на попытку парламентских партий, мухлюя в 8 рук, „перекрыть кислород” остальным, это мало похоже: на графике явно „непроходной” АПР пики в районе 70% и 80% тоже заметны. Единственное внятное предположение, которое у меня в связи с этим возникает — это что по крайней мере в некоторых случаях „круглая” явка создавалась путём „чистого”, такскзть, вброса: добавлялись голоса не за ЕР, а за все партии более-менее равномерно. Зачем? А именно для того, чтобы отчитаться по явке, не более. Это объясняет происхождение пиков по числу поданых голосов в районе „круглых” явок у всех партий, а не только ЕР. Что, собственно говоря, опровергает ваше предположение о подтасовке результатов в пользу ЕР — по крайней мере, в тех объёмах, о которых вы говорите.
В общем, получается, что имеют место 2, а 3 типа голосующих:
а) те, что голосуют „нормально”;
б) те, что аномально голосуют при высоких явках, но без нарушения распределения голосов по партиям/кандидатам (просто повышают явку);
в) те, что аномально голосуют только за ЕР (тем самым и повышая явку).
Вследствие такой ошибки (объединения групп „б” и „в”) вы сильно завышаете масштаб предполагаемых подтасовок в пользу ЕР.
QED ;-)
На Ваш вопрос о «мухлеже в пользу остальных партий» могу предложить такую версию:
Кроме вброса есть еще технология простого преступного перезачтения голосов от одних- другим (ну понимаете, кому). Это может происходить вообще потом, после подсчета бюллетеней, при играх цифрами на бумаге. Почитайте отзывы, как наблюдателей отодвигали на расстояние, при котором они не видели «галочки» во время подсчёта. В такой ситуации абсолютно не важно, как стоят галочки- важно, что написано в протоколе.
Если имеем ограниченное (конечное) количество бюллетеней в урне, то для увеличения голосов у одних надо эти голоса отнять у других. (Хотя и здесь ОНИ иногда не дружат со здравым смыслом и накручивают более 100% голосов, что также подтверждает манипуляции).
В результате «ручных» операций естественным образом возникают «круглые» цифры- как у лидера, так и у обиженных. Ведь тот, кто цифры рисует, по определению туп, недалёк и ленив. У него другие приоритеты по жизни.
В любом случае ожидать фантазии не приходится.
И рисуют ОНИ одним 50, другим 20, третьим 15, четвертым 10, осталось 5- их раскидали между остальными. Круглые цифры.
Их просто легче считать.
:)
Я, например, точно знаю, что ЛДПР меньше 13% набрать не может- это процент психически ненормальных в любой выборке людей, спросите у психиатров.
На протяжении 90х и начале 2000х ЛДПР и набирала свои 13%- а вот в последние годы этот процент уменьшился. И это тоже косвенное доказательство манипуляций.
Все проще. Вброс голосов за одну кандидатуру меняет распределение участков по явке и соответственно искажает распределения голосов за все кандидатуры. При вбросе бюллетеней (или приписывания голосов) за кандидатуру власти до круглых значений явки на этих круглых значениях явки группируется аномально много избирательных комиссий. Естественно, голосов за другие партии в соответствующих интервалах явки тоже оказывается больше. Но величина пика за кандидатуру власти относительно больше, чем за остальные кандидатуры.
Да, такое соображение тоже правдоподобно.
Осталась невыясненной технология вброса.
Чтобы вбросить до круглой цифры, надо как минимум сопоставить два числа: число выданных на данном участке бюллетеней (это можно посчитать по журналу) и число реально проголосовавших за сами-знаете-кого, посчитать реальный процент.
Далее решить задачу для пятого класса: сколько надо добавить правильных бюллетеней, чтобы конечный процент оказался круглым (с учетом того, что общее количество будет новое), при этом иметь в виду ограничение в виде общего числа зарегистрированных избирателей.
Предложенная мной версия не предполагает великих умственных усилий: бюллетени сами собой, а протоколы- сами собой. Вероятность возникновения судебного решения, которое приведёт к пересчету бюллетеней, близка к нулю (см. ролики в Интернете, как вела себя полиция на участках).
Единственный известный случай с Митрохиным, описанный в Вашей статье, стопроцентно :) подтверждает мою версию.
В любом случае результат очевиден: применение статистического анализа результатов вскрывает подтасовки на выборах.
Спасибо Вам за это.
Думаю, что реально подгонка под круглые проценты происходит уже на стадии заполнения протокола, когда комиссия прикидывает, выполнен спушщенный план или нет. Если нет — дописывают до нужного процента. Естественно, введением дополнительного разброса никто не занимается, так что результаты концентрируются на круглых числах.
Сергею Шпилькину:
http://cifidiol.livejournal.com/1600.html
А вот история, которая явно свидетельствует, что можно сколько угодно теоретизировать и проявлять высокий академизм.
Реальная жизнь намного груба и жестока.
Голосование НИЧЕГО НЕ ЗНАЧИТ.
В полном соответствии с измес ным выражением известного лица: «Нэважно, как голосовали, важно- как подсчитали».
http://oude-rus.livejournal.com/540063.html
Спасибо, очень интересная статья, не теряющая актуальности.
Если можно, хотел бы прояснить для себя небольшой математический момент по последним абзацам статьи.
Если я правильно понял задачу, то находится вероятность события, при котором из 904 бюллетеней, каждый из которых с вероятностью 22/116 неверно учтен, не будет ни одного неверно учтенного.
Мне тут видится чисто биномиальное распределение(904,22/116), и тогда вероятность такого события я нахожу, как: C(904,0)*(22/116)^0*(1-22/116)^(904-0)=(94/116)^904, что дает на много порядков меньший результат…
У меня была чуть другая модель: взяли 1120 бюллетеней, случайным образом неверно учли ровно 22. Какая вероятность, что все неверно учтенные оказались среди 116 за остальные партии, а не среди 904 за ЕР. Число другое, но принципиально ничего не меняется.