Публикуем полную версию комментария Алексея Куприянова, доцента Департамента социологии Санкт-Петербургского филиала НИУ ВШЭ, посвященного контексту и анализу итогов опроса ВЦИОМ (31.12.15-01.01.16). В бумажной и pdf-версии газеты опубликован сокращенный вариант этой статьи.

Менее всего я хотел бы, чтобы мой комментарий воспринимался как копание в технических деталях. Мое общее мнение состояло и состоит в том, что ни одна уважающая себя опросная фирма не должна была соглашаться на проведение этого опроса по целому ряду причин.
Во-первых, потому что, по сути, мы имеем дело не с опросом общественного мнения (какой бы спорной ни была сама концепция общественного мнения), а с демонстративным распределением ответственности за политические авантюры правительства России на население Крымского полуострова. Во-вторых, потому что формулировки вопросов носили явно манипулятивный и провокационный характер (включая уголовную ответственность за один из вариантов ответа).
В-третьих, потому что в условиях, когда профессиональная автономия подавлена до такой степени, что невозможно ни скорректировать формулировки, ни расширить разумным образом список вопросов (например, самые очевидные вопросы «Сталкивались ли Вы уже с отключениями электроэнергии?», «Имеется ли у вас электроснабжение прямо сейчас?» так и не были заданы), вообще не ясно, ни зачем, ни как его проводить.
Помимо этого остаются однако еще технические вопросы, касающиеся процедур сбора и анализа данных. Их также необходимо обсуждать. В значительной мере, потому что, судя по обсуждениям, идущим в последнее время на открытых и закрытых площадках Интернета, многим кажется, что здесь все обстоит благополучно (в стиле: да, вопросы сформулированы не лучшим образом, да, политический заказ очевиден, но, по крайней мере, «ремесленная» составляющая отработана честно).
Моя заметка – о том, что эти ожидания, судя по всему, не оправдываются. Для того, чтобы понять, почему, необходимо внимательно вглядеться в результаты опроса.
Переходя к анализу результатов, я, прежде всего, хотел бы поблагодарить сотрудников ВЦИОМ и лично Валерия Фёдорова за то, что массив данных (dataset) по опросу был выложен на общее обозрение на сайте ВЦИОМ и за готовность дополнить его рядом переменных по просьбам социологов (надеемся, что обновленный расширенный dataset позволит ответить еще на несколько вопросов).
Массив данных включает 3025 записей, содержащих сведения по 14 переменным (основные: населенный пункт / тип населенного пункта, пол, возраст с точностью до года, уровень образования, ответы на первый и второй вопросы, возраст с точностью до возрастной когорты, начало, конец и длительность интервью с точностью до секунд, регион, дата интервью и «весовой» коэффициент ответа).
Начну с очевидного. По сути, мы имеем дело с выборочным дизайном исследования (и, стало быть, попыткой оценить по параметрам выборки параметры всего населения полуострова). Все, кто знаком с этим типом исследовательского дизайна, знают, что желательно было бы, чтобы выборка удачно моделировала население (корректно репрезентировала его) по исследуемым параметрам.
Проблема в том, что распределение исследуемых параметров в популяции обычно неизвестно. Теоретически можно ожидать, что желаемого можно добиться при помощи рандомизированной (случайной) выборки. В каком смысле она должна быть случайной? Критерий отбора не должен, по крайней мере, порождать систематической ошибки в отношении исследуемого параметра. Работая вслепую, применяют различные процедуры рандомизации («ослучаивания») выборки, о которых довольно подробно написано в каждом учебнике по методам исследований, каких бы предметных областей они ни касались.
Достаточно строгое применение этих процедур дает надежду на то, что мы не внесли систематической ошибки на этапе сбора данных и не получим значительного смещения оценок параметров популяции. Однако полной уверенности никогда быть не может. Именно поэтому необычайно важны тщательные описания методов, которые дают надежду на выявление источников систематической ошибки при дальнейших исследованиях.
Наше положение несколько проще, когда мы знаем какие-то параметры популяции. В таких случаях мы можем проверить успешность рандомизации по тому, насколько хорошо выборка моделирует популяцию по этим известным параметрам (это особенно важно, если мы подозреваем, что эти параметры могут быть как-то связаны с нашим «неизвестным»).
Из имеющихся в нашем распоряжении параметров опроса ВЦИОМ мы можем ориентироваться на социально-демографические (пол, возраст, образование) и географические (индивидуализированный крупный населенный пункт, например, Севастополь или Симферополь, или тип населенного пункта). По счастью, социально-демографические параметры и распределение жителей по населенным пунктам для населения Крыма более-менее известны, благодаря прошедшей осенью 2014 года переписи населения.
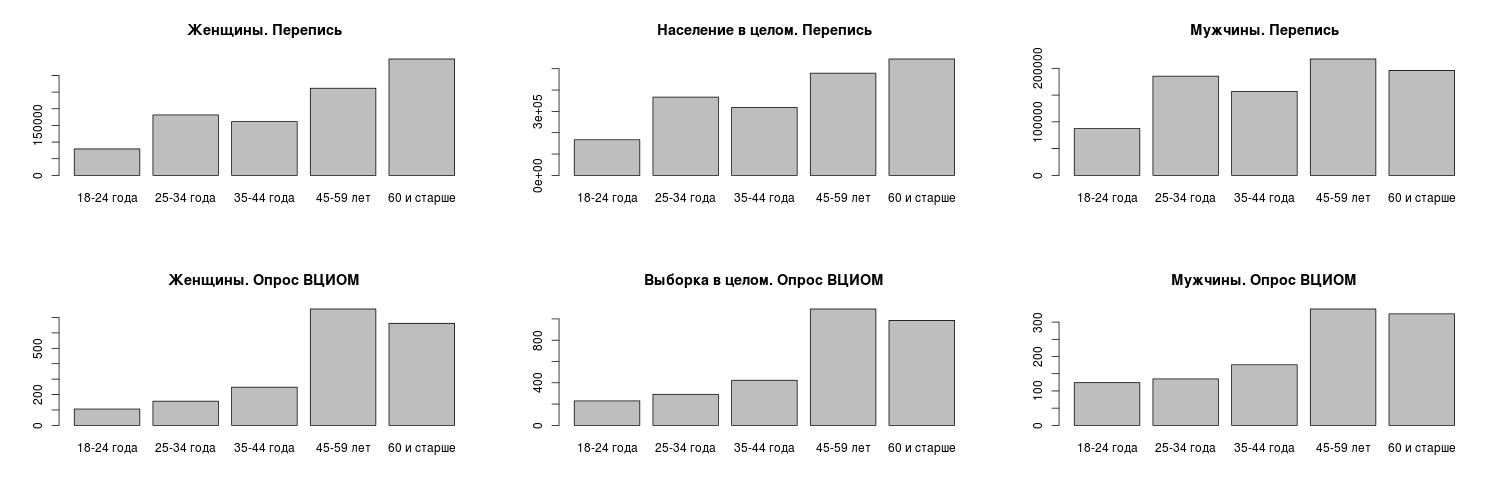
Экспресс-тестирование показало, что выборка ВЦИОМ существенно отличается от данных переписи по ряду параметров. Коротко говоря, эти отличия сводятся к следующему: в выборке ВЦИОМ избыточно представлены старшие возраста и женщины и недопредставлены молодежь / средний возраст и мужчины (см. табл. 1–2 и рис. 1–2). Это само по себе может быть лишь свидетельством систематической ошибки самого телефонного опроса как метода достижения респондентов (что вряд ли может радовать, но, по крайней мере, не катастрофично). Однако, помимо этого, обращает на себя внимание еще ряд странностей.
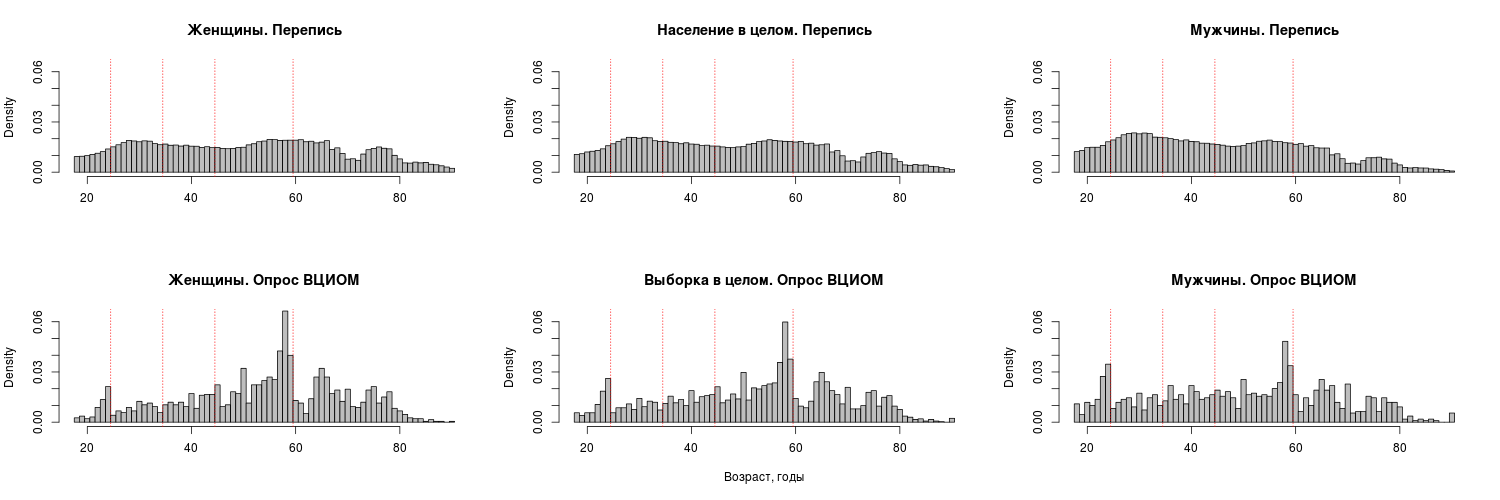
При анализе, помимо описанных «больших» смещений в пользу женщин и старших возрастов и небольших пиков на кратных пяти значениях возраста в годах, привлекают внимание аномальные пики на возрастах 24 и 57–59 лет. Можно высказывать различные предположения о том, чем они обусловлены (например, техникой ведения интервью, когда интервьюер произвольно приписывает респонденту какой-то возраст при уклончивом ответе), однако без дополнительных данных их проверить невозможно.
Таблица 1. Сопоставление структуры населения по данным переписи 2014 года и структуры выборки опроса ВЦИОМ: соотношение полов (X-squared=91,248; df=1; p-value<2,2*10-16).
| Перепись | Опрос | |||||
| Наблюдаемое | Теоретически ожидаемое | Пирсоновские остатки | Наблюдаемое | Теоретически ожидаемое | Пирсоновские остатки | |
| Мужчины | 843330 | 843068,4 | 0,2849285 | 1097 | 1358,62 | -7,10 |
| Женщины | 1033785 | 1034046,6 | -0,2572748 | 1928 | 1666,38 | 6,41 |
Табл. 2. Сопоставление структуры населения по данным переписи 2014 года и структуры выборки опроса ВЦИОМ: соотношение возрастных когорт, использованных аналитиками ВЦИОМ при подведении итогов (X-squared = 318,82; df = 4; p-value < 2,2*10-16).
| Перепись | Опрос | |||||
| Наблюдаемое | Теоретически ожидаемое | Пирсоновские остатки | Наблюдаемое | Теоретически ожидаемое | Пирсоновские остатки | |
| 18–24 года | 166951 | 166912,0 | 0,09541412 | 230 | 268,98 | -2,376815 |
| 25–34 года | 366910 | 366611,2 | 0,4934887 | 292 | 590,80 | -12,293059 |
| 35–44 года | 318718 | 318628,5 | 0,15851067 | 424 | 513,47 | -3,948583 |
| 45–59 лет | 479027 | 479347,5 | -0,46295132 | 1093 | 772,48 | 11,532357 |
| 60 лет и старше | 545509 | 545615,7 | -0,14449415 | 986 | 879,27 | 3,599424 |
Определенно можно сказать одно. Попытка локализации этих аномалий довольно быстро привела к неожиданному и не очень приятному результату. Эти пики возникают только в той части выборки, которая была собрана 1 января 2016 года, причем они заметны во всех типах населенных пунктов.
Половозрастная структура части выборки, собранной 31 декабря 2015 года, более гомогенна. Будучи вдвое меньшей по объему, эта часть, хотя и не соответствует данным переписи по половозрастной структуре, по крайней мере, лишена неестественных обширных провалов и пиков, характерных для возрастной структуры выборки 1 января (см. рис. 3).
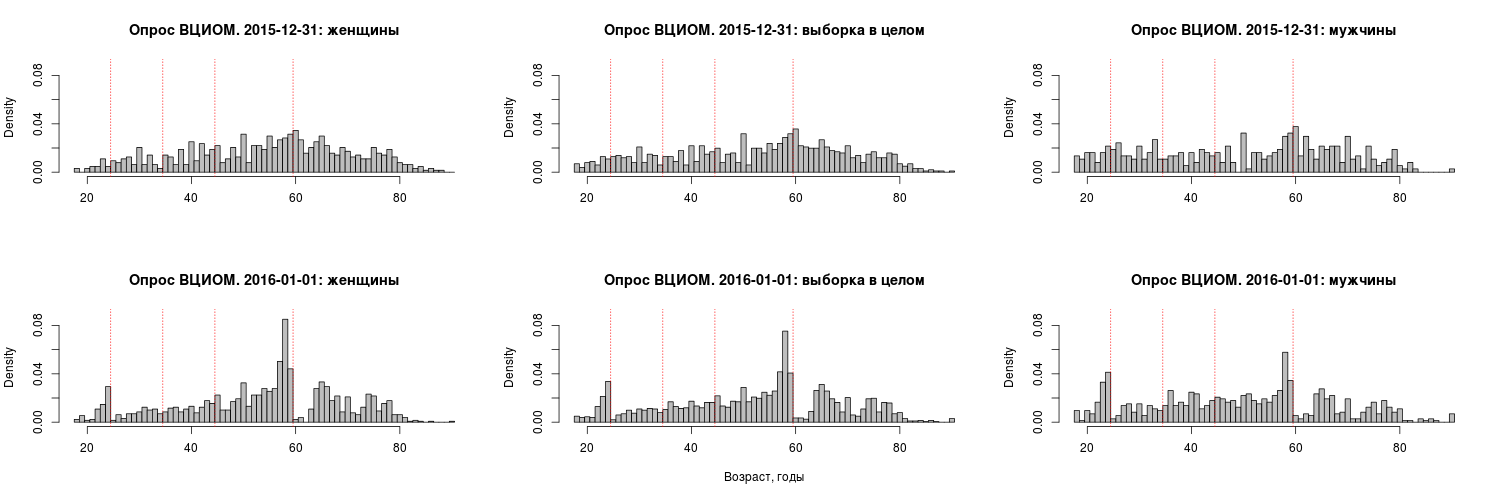
Это «открытие» важно в контексте уже раскрытых сотрудниками ВЦИОМ деталей организации опроса. Дело в том, что, по словам представителей ВЦИОМ, вторая часть выборки была сформирована после того, как стало ясно, что первая тысяча респондентов набрана еще 31-го числа. Более того, если сравнить первый и второй день опроса по возрастным когортам, использованным ВЦИОМ для представления агрегированных данных, то выяснится, что подвыборки этих двух дней на высоком уровне значимости отличаются друг от друга.
В первый день относительно второго избыточно представлены вторая и пятая когорты (25–34 года и 45–59 лет), недопредставлены первая и четвертая (18—24 года и 60 и более лет) и лишь с третьей (35–44 года) нет никаких проблем (см. рис. 4 и табл. 3).
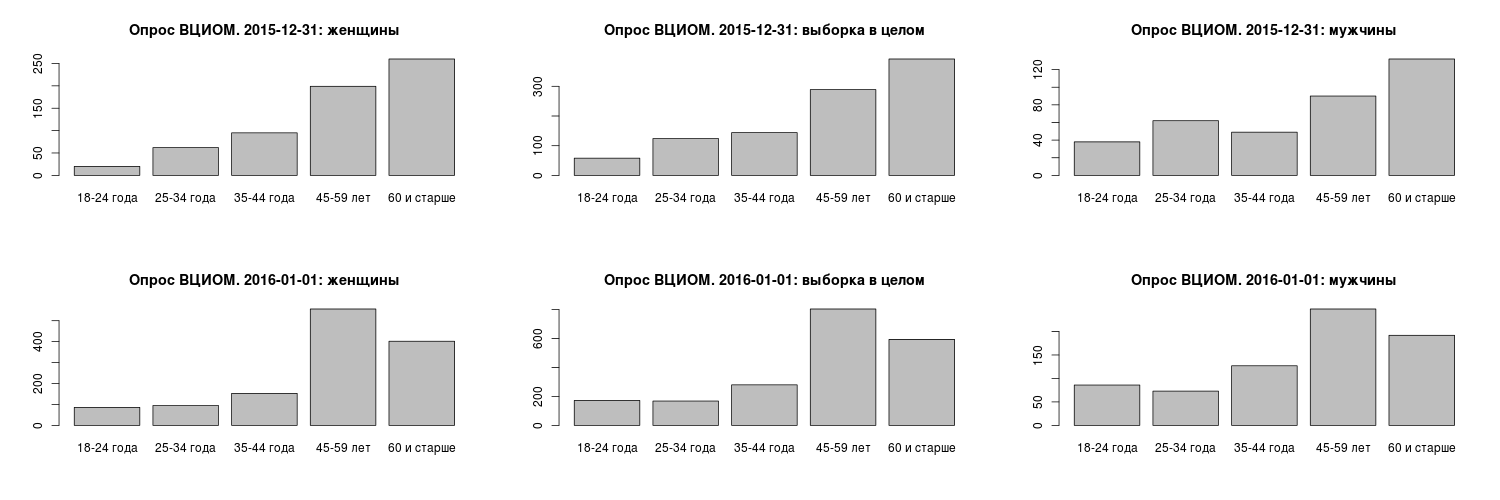
Табл. 3. Сопоставление выборок за 31 декабря 2015 г. и 1 января 2016 г. по возрастным когортам, использованным аналитиками ВЦИОМ при подведении итогов (X-squared = 59,56; df = 4; p-value = 3,589*10-12).
| Перепись | Опрос | |||||
| Наблюдаемое | Теоретически ожидаемое | Пирсоновские остатки | Наблюдаемое | Теоретически ожидаемое | Пирсоновские остатки | |
| 18–24 года | 58 | 76,57 | -2,1217087 | 172 | 153,43 | 1,498787 |
| 25–34 года | 124 | 97,20 | 2,7177926 | 168 | 194,80 | -1,919864 |
| 35–44 года | 144 | 141,15 | 0,2401879 | 280 | 282,85 | -0,1696701 |
| 45–59 лет | 289 | 363,85 | -3,9240885 | 804 | 729,15 | 2,7719982 |
| 60 лет и старше | 392 | 328,23 | 3,5197502 | 594 | 657,77 | -2,4863714 |
По сути, это говорит о том, что мы вряд ли можем рассматривать подвыборку 31 декабря 2015 года и подвыборку 1 января 2016 года как части одной выборки. До появления дополнительной информации о ходе опроса трудно сказать, с чем конкретно может быть связан этот эффект, однако «рваное» распределение по возрастам при вдвое большей численности респондентов 1 января определенно указывает на нарушение процедур рандомизации и/или интервьюирования.
Это, в свою очередь, ставит под сомнение возможность использования в анализе данных за этот день в целом или, по меньшей мере, сужение возможностей для анализа в виду необходимости исключения ряда переменных.
Говоря без обиняков, это означает, что, если данные за 31 декабря еще как-то можно анализировать, то данные 1 января собраны настолько некачественно, что использование их в анализе практически не имеет смысла (это в значительной мере обесценивает тонкие наблюдения Кирилла Калинина в заглавной статье, хотя, парадоксальным образом, совместимо с некоторыми его общими выводами, поскольку он выявил изменение результатов опроса от первого ко второму дню).
Отдельного обсуждения заслуживает проблема другого рода – что осталось скрытым от нас в результате того, что выборка имеет столь серьезные смещения? Аналитики ВЦИОМ предположили, что достаточно скорректировать вес каждого ответа при помощи коэффициента, учитывающего пол, возраст и населенный пункт. Это однако верно лишь в том случае, если мы предположим также, что эти страты достаточно гомогенны и удачно репрезентированы в выборке (кроме того, в коэффициентах никак не был учтен фактор даты опроса, который, как мы уже знаем, оказал существенное влияние на ряд параметров).
Этот аспект тем более трудно анализировать до тех пор, пока не получены данные о недоступе (до абонента не удалось дозвониться) и об отказах от интервью. Из отрывочных сведений уже можно предполагать, что не сохранена информация о том, чем обусловлен недоступ (линия занята, абонент не отвечает, мобильный абонент отключен или находится вне зоны действия сети).
Ввиду того, что значительная часть современных стационарных телефонов требует дополнительного питания от сети, а мобильные устройства требуют подзарядки, выборка могла быть смещена в пользу людей, находящихся вне зон отключения электроэнергии. По отказавшимся от интервью, судя по всему, не фиксировалась никакая информация (хотелось бы надеяться на то, что эту проблему можно решить хотя бы для стационарных телефонов).
Невозможность проконтролировать хотя бы один из параметров (география, пол) «отказников» не позволяет никак охарактеризовать часть населения, эксплицитно отказавшуюся от участия в опросе (и оценить вклад «отказов» в смещение выборки). Проблема может быть решена лишь раскрытием дополнительных данных по крымскому опросу и аналогичных данных по другим опросам, но на настоящий момент мы ими не располагаем.
В ходе обсуждения высказывались различные гипотезы, в том числе, о том что опрос вообще не проводился, а результаты его полностью фальсифицированы. Должен разочаровать наиболее радикальных критиков. Опрос, судя по всему, был проведен, хотя в его организации остается ряд непроясненных моментов. Вместе с тем, судя по состоянию собранных данных, качество проведения опроса оставляет желать много лучшего. Систематические различия параметров выборок 31 декабря и 1 января по своему характеру не могут быть объяснены причинами на стороне респондентов и говорят о серьезных проблемах с дизайном исследования.
В ходе обсуждения не раз высказывалось мнение, что крымский опрос не принес нам ничего нового (в результате опроса подтвердился высокий уровень поддержки действий Правительства РФ), поскольку по результатам предыдущих исследований не приходится сомневаться, что уровень декларируемой поддержки должен быть высоким. Однако я совершенно не понимаю, как при таком небрежении к дизайну исследований, который сквозит в массиве ВЦИОМа, можно быть уверенными, что мы вообще можем утверждать, что что-то может или не может нас удивить.
Возможно, эта небрежность может быть обусловлена различием задач работников опросных служб и социологов. Первых, особенно в столь очевидно «заказных» исследованиях, интересует лишь примерное соответствие желаемому результату, ради которого можно пренебречь огрехами в дизайне исследования. Вторых должно бы интересовать «действительное положение дел», которое может быть выяснено только в результате безукоризненного следования исследовательской процедуре и постоянной критической перепроверки гипотез, в том числе, о качестве собираемых данных.
Так, в обсуждениях мне указывали, что опросные фирмы намеренно избегают формирования рандомизированных выборок, поскольку это-де трудоемкий процесс, потому и используются разного рода неслучайные выборки и post hoc калибровочные коэффициенты для приблизительной оценки ситуации. Это однако хорошо, когда у нас есть независимые методы оценки, которыми мы можем откалибровать метод.
Вместе с тем, еще свежа в памяти история с предвыборными предсказаниями, которые, будучи неоднократно «откалиброванными» по материалам массово фальсифицированных выборов, превратились в инструмент по подгонке неудобных данных под заведомо ложный результат (что не замедлило проявиться, как только была дана команда «считать честно», выборы в Москве прошли без массовых фальсификаций, а опросная индустрия была вынуждена признать свое поражение, «промахнувшись» на десятки процентных пунктов). Эта намеренная утрата связи с реальностью представляется мне довольно опасной, поскольку в текущей кризисной ситуации можно в результате пропустить социальный взрыв нешуточной силы.
Главное не в том, что в результате более тщательно проведенного исследования антиправительственная позиция могла бы набрать или потерять несколько процентных пунктов, а в том, что на повестку дня вынужденно встает вопрос: можно ли вообще использовать собранные таким образом данные для сколько-нибудь обоснованных выводов о чем бы то ни было, кроме как о неудовлетворительном качестве данных.
Примечание 1. Пока я писал этот текст, выяснились дополнительные подробности. Как сообщили сотрудники ВЦИОМ, после нескольких часов опроса они изменили спектр предлагаемых респондентам вариантов ответа, убрав из него вариант «затрудняюсь ответить». Результатом этого стало довольно интересное с точки зрения социальной психологии явление, радость от обнаружения которого смазывается тем, что данные собраны настолько небрежно, что его будет трудно корректно описать.
Как только респондентам перестали зачитывать вариант «затрудняюсь ответить», упала и доля людей, выбирающих «правительственно-неодобряемый» вариант ответа. Это, возможно, означает, что к стану «конформистов» примкнула не только та категория граждан, которая ранее колебалась в выборе ответа, но и какая-то часть бывшей «оппозиции». Если это действительно так, то это дает довольно наглядный пример влияния конкретных формулировок и способов «закрытия» на результаты опроса. Неприятная сторона этого эффекта в том, что мы снова в результате больше узнаем об инструменте, чем о том, что надеялись с его помощью измерить.
Примечание 2. Для желающих, к статье приложен скрипт (*.zip), написанный для работы в среде статистического программирования и анализа данных R, при помощи которого были выполнены все необходимые для написания этого текста расчеты и иллюстрации. На его основе любой человек, владеющий R, может воспроизвести и продолжить анализ самостоятельно. Для работы с ним необходимо также скачать с сайта ВЦИОМ архив с данными (см. http://wciom.ru/index.php?id=237&uid=115540), распаковать его и переименовать извлеченный из архива файл в crimea.sav
«По сути, это говорит о том, что мы вряд ли можем рассматривать подвыборку 31 декабря 2015 года и подвыборку 1 января 2016 года как части одной выборки. » — Вы серьезно?))
Это как бы совсем логично, что результаты опроса 31 декабря и 1 января должны отличаться по вполне себе объективным причинам, даже на нормально рандомизированной выборке и практически по любому поводу) Праздник же!) Причем праздник как у жителей Крыма, так и у сотрудников ВЦИОМ. Причем почти обязательно связанный с обильным потреблением алкоголя с ночь с 31 на 1(Ваш КО.)
Интересно, кто вообще придумал проводить опрос в эти числа, наверное человек с юмором;)
Мои родственники, которые живут в Севастополе, а также их соседи, знакомые и сослуживцы услышали об этом опросе уже после того,как он произошел.
Спасибо автору за подробный анализ. Интересно, каким был бы процент согласившихся, если бы опрос проводили в соответствии с социологическими нормами. Конечно, правительству совершенно нужен не точный результат, а 96% «за», а то и 146%.