
На днях в открытый доступ было выложено исследование «Антиплагиата», проведенное на данных Научной электронной библиотеки eLIBRARY.ru [1], выявившее 70 407 случаев дублирования публикаций [2] в российских научных изданиях. Подробная информация об исследовании приведена в [3], и значительная часть собранных текстов представляет собой примеры неэтичного дублирования. Что означают полученные цифры и что делать университетам, авторам и журналам с этой информацией?
Исследование получилось беспрецедентным, аналогов ему в мире пока нет. Но не потому, что в мире нет недобросовестного дублирования статей или недобросовестных авторов. Уникальность исследования обусловлена особенностями базы НЭБ, для которой длительное время был характерен низкий уровень требований на входе — туда выгружались российские научные журналы самого разного уровня. Так что пока нельзя достоверно сказать, лучше или хуже отечественная ситуация по параметру количества дублирующих публикаций относительно других стран. Да, еще один ключевой момент: западные исследования обычно сравнивают дубли по библиографии, а в настоящем исследовании сравнение шло по текстам статей.
Важно не забывать, что не всякая дублирующая статья плоха. Бывают добросовестные дублирования, связанные с переводом на другой язык, расширением читательской аудитории (когда один текст публикуется, например, в социологическом и медицинском журналах). Однако все подобные случаи отличает наличие ссылки на предыдущую публикацию, такие материалы не вводят в заблуждение относительно новизны и оригинальности текста.
Недобросовестные дублирующие публикации появляются по конкретным причинам. Например, автор хочет создать иллюзию приращения научного знания, «накрутить» наукометрические показатели, обмануть работодателя или грантодателя (отчитавшись одной статьей вместо нескольких)… И всё это в конечном счете ведет к искажениям в метааналитических исследованиях, в наукометрических показателях, к ненужной перегрузке редакторов и рецензентов и нарушает авторские права.
Статистика появления дублирующих публикаций показывает, что их интенсивность коррелирует с повышением требований университетов к публикационной активности своих сотрудников. То есть в ряде случаев появление подобных текстов можно расценить как своего рода результат провокации на преступление со стороны системы образования. Не имея ресурсов на написание полноценных научных статей, авторы вынужденно выбирали путь наименьшего сопротивления, отчитываясь дублирующими статьями. Это, конечно, не оправдывает, но объясняет произошедшее.
При этом мы видим некоторый спад в количестве таких статей, начиная с 2017 года. Возможно, он связан с тем, что в этом году усилиями Совета по этике научных публикаций в России впервые была введена практика ретрагирования статей, содержащих дублирования, плагиат, фальсификации и фабрикации. Возможно, это тот самый случай, когда низовая гражданская инициатива сработала эффективнее, чем государственные механизмы. Повторный анализ позволит подтвердить или опровергнуть данную гипотезу (рис. 1).
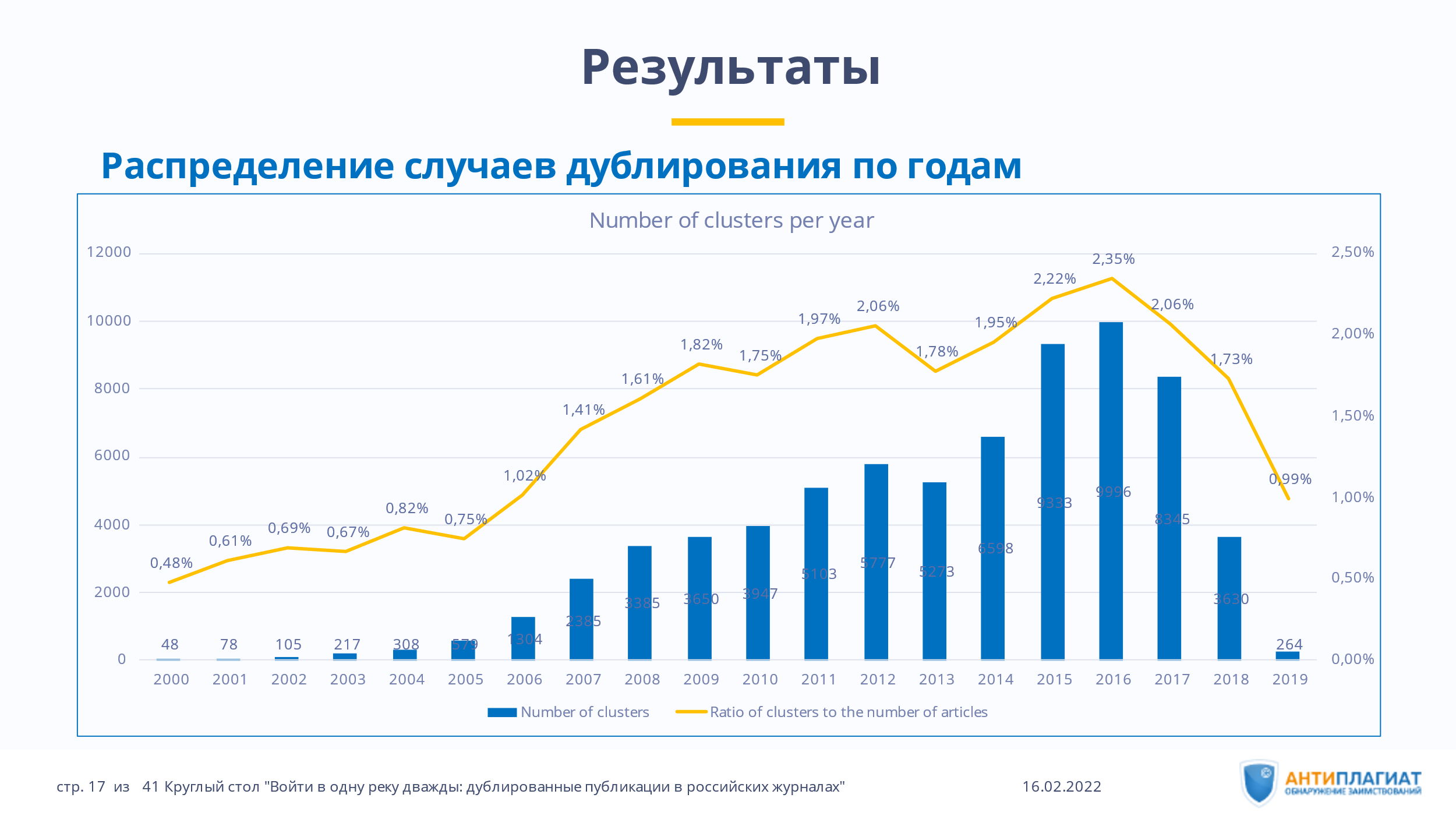
Отмечу, что не только ученые и преподаватели являются инициаторами появления таких дублирующих статей, — иногда журналы, испытывая дефицит материалов, публикуют понравившиеся тексты из других изданий, не информируя об этом автора. В таком случае материал достаточно легко ретрагировать (указав в качестве основания отзыва статьи нарушение норм этики научных публикаций со стороны журнала), поскольку договор с автором на публикацию не заключался.
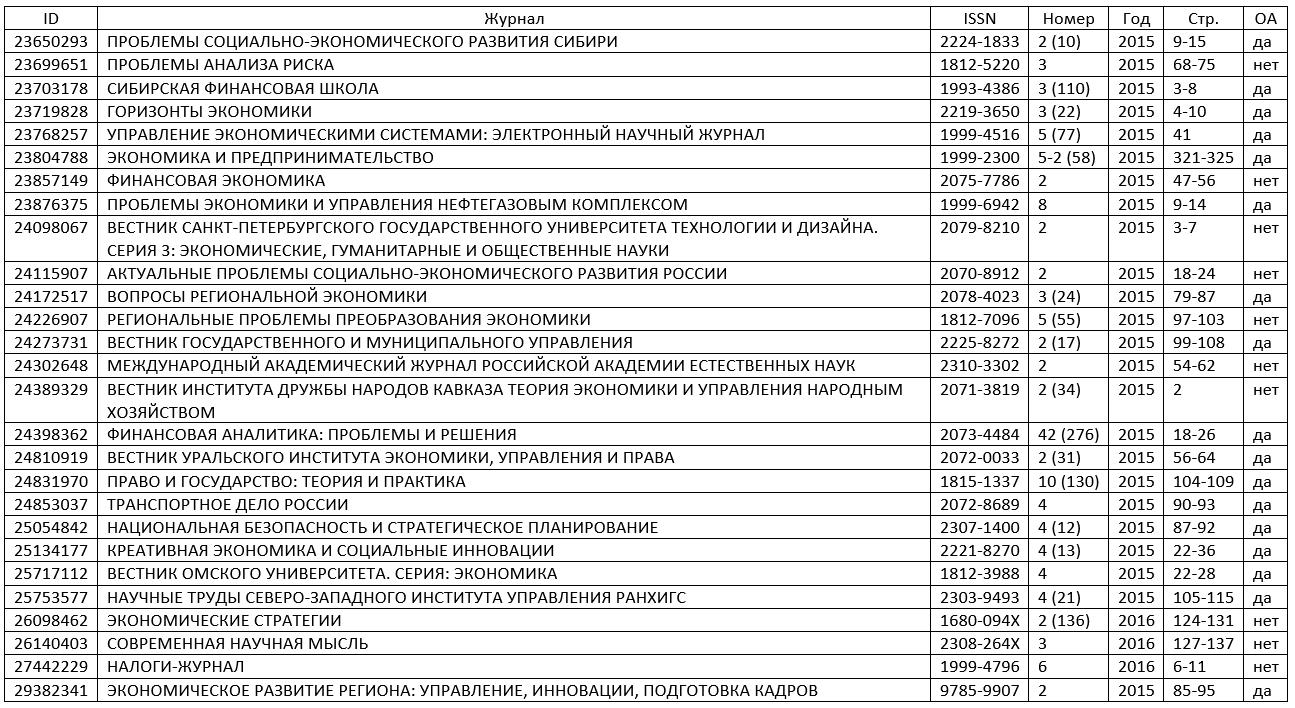
В качестве примера недобросовестных дублирований, выявленных в ходе исследования «Антиплагиата», приведу два случая. Первый — двадцать семь статей со средним пересечением текста в 83,55% с одним общим соавтором — С. А. Владимировым. Все статьи опубликованы в разных научных журналах, в 6 из 27 статей присутствуют соавторы. Так как тексты всех 27 опубликованных статей отличаются незначительно, то случаи соавторства можно отнести к приписному или подарочному авторству, то есть к нарушениям норм научной этики (рис. 2).
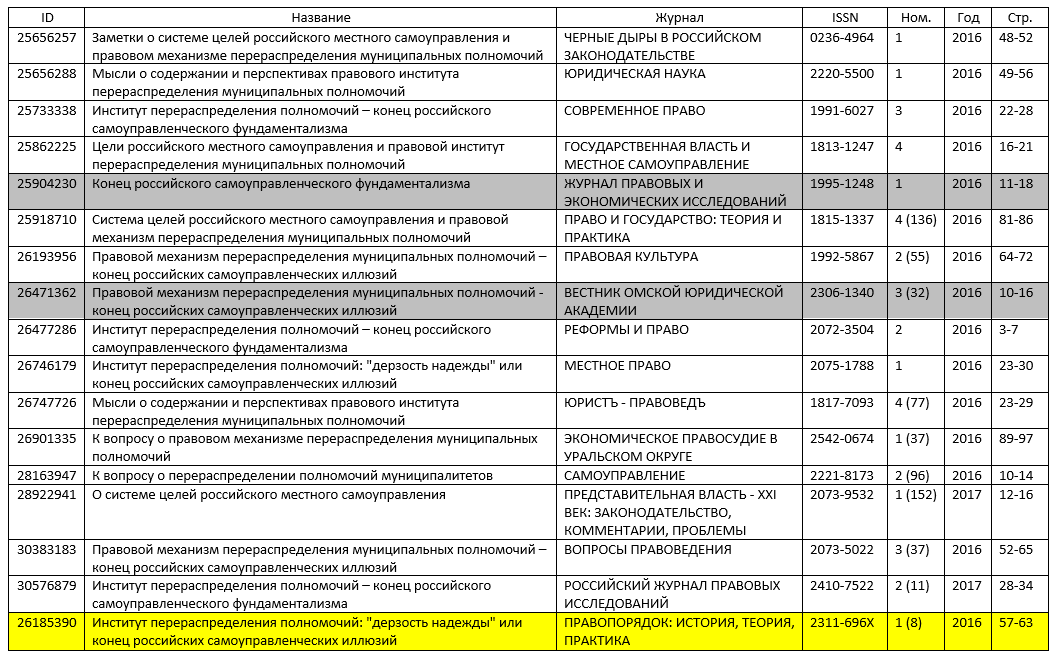
И еще один кейс. Шестнадцать статей со средним пересечением текста 89,43%. У всех статей один автор — С. Г. Соловьев, они опубликованы в разных журналах, две из них вышли в 2017 году, остальные — в 2016 году (рис. 3).
Какие же выводы стоит сделать авторам, журналам и университетам при анализе 70 тыс. выявленных случаев дублирования статей?
Во-первых, стоит поблагодарить авторов исследования. Работу по выявлению дублирований надо было провести давно, и полученные данные — серьезная помощь и опора для всех, кто заинтересован в улучшении ситуации в российской науке и образовании.
Во-вторых, важно вдумчиво проанализировать случаи, касающиеся вас лично (если вы нашли свое имя в этой базе), ваших университетов или журналов, понять, что за ними стоит. Недопустимо ответственность перекладывать с человека на машину. Доверяем, но проверяем. Компьютерный поиск и сравнение выявляют только объем повтора текста, но интерпретация и анализ остаются за человеком.
В-третьих, подтвержденные недобросовестные дублирующие публикации стоит ретрагировать. Это будет полезно сразу в двух смыслах: продемонстрирует здоровое отношение всех акторов (допущенная ошибка исправляется) и поможет снизить наукометрические искажения.
В-четвертых, важно осознать, что с открытыми данными будут работать все — от «Диссернета» до составителей рейтингов университетов, журналов и пр. Если университеты и журналы по своей инициативе не займутся ретрагированием дублирующих публикаций, то это будет определенным образом характеризовать их: им либо безразлична собственная репутация, либо безынтересны наука как таковая, информационный шум, создаваемый дублирующими текстами, разного рода искажения.
В-пятых, если вы являетесь представителем университета, принимающим управленческие решения, и имена ваших сотрудников оказались в этой базе данных, то стоит ответить на вопрос «почему?». Почему во вверенном вам университете ситуация по нарушениям этики научных публикаций именно такая, а не другая? Что мотивирует ваших сотрудников на неэтичное поведение? Поощряется ли этичное? Допустим, если один сотрудник напишет десять плохих статей, а другой — одну хорошую, с кем вы продлите контракт и кому доплатите за публикации?
В-шестых, ни в коем случае не разворачивала бы карательные кампании против журналов, авторов и университетов, попавших в эту базу. С одной стороны, это лишь вершина айсберга, мы еще многое не знаем про другие издания, учебные заведения и авторов; с другой — важно помнить, что цель подобных исследований — не наказание, а исправление ошибок.
And the last but not the least. В современном мире от людей требуются высокие социальные компетенции по многим и многим направлениям. Если вы родитель, то вам приходится разбираться в вопросах здоровья и образования, если вы издатель или автор — самостоятельно следить за обновлениями в международных стандартах, изменением практик. Но, на мой взгляд, родителем быть тяжелее, ведь на помощь авторам и издателям могут прийти Совет по этике научных публикаций, «Диссернет», Комиссия РАН по противодействию фальсификации научных исследований, Общество научных работников, РИНЦ и многие другие проекты и инициативы, содействующие развитию цивилизованной научной сферы в нашей стране. Улучшение ситуации с этикой науки и публикационной этикой — задача всего сообщества. Давайте работать над ней вместе.
Анна Кулешова, социолог, член Комиссии РАН по противодействию
фальсификации научных исследований и Совета по этике научных публикаций
База кривущая. Я поискал в ней статьи своего института, нашел три случая со знакомыми фамилиями и проверил их — и все три явные ошибки, три из трех. В одном случае ошибка елибрари — там почему-то одна статья фигурирует два раза, один раз правильно и один раз ошибочно с неверными выходными данными. Второй случай — материалы конференции и вступительная статья к материалам конференции (написанная другим человеком, видимо, председателем программного комитета). Возможно, в этой вступительной статье цитируется первая, а может, и нет — я не проверял; но абстракты очевидно разные. И последний случай из трех — две соседние статьи в одном номере журнала. Статьи разных авторов и совершенно разные, хотя и на близкие темы. При этом указано совпадение 95 %.
Все статьи по физике.
То есть при таком уровне ошибок нет смысла серьёзно относиться к такой базе. По крайней мере в естественных науках, где уровень плагиата невелик и ниже уровеня ложных срабатываний автоматической проверялки.
Алексей, ошибки не исключены. Скорее всего журналы, которые и заливают тексты на elibrary, поместили тексты, которые не соответствуют метаданным. Пожалуйста, сбросьте id мне на почту, мы разберемся и внесем исправления.
Алексей, ошибки не исключены. Данные на elibrary заливают журналы и делают это вручную. Вполне могли поместить один и тот же полный текст по разным метаданным. Пожалуйста, пришлите id мне в почту, мы проверим нет ли ошибки.
Я не вижу смысла исправлять отдельные ошибки, когда там целые кластеры таких ошибок — в статье вы сами об этом говорите. Например, записи с очень близкими id статей, но с разными авторами и с очень высокой долей совпадения — очевидные ошибки. Таких записей много и они соответствуют какому-то неверному распознаванию соседних статей в одном номере журнала. Типичный пример — последняя строчка вашего экселевского файла. Все такие случаи можно было бы легко вычистить нехитрым скриптом.
Алексей, во-первых спасибо Вам, что попробовали поработать и разобрались. Мы знаем о проблеме серьезного совпадения текстов с близкими id. Как я сказал раньше, самая вероятная причина этого — неверная заливка издателями текстовой подложки в базу elibrary. Во-вторых, мы завели в данных специальное поле, чтобы «подсветить» эти проблемы (название поля — suspicious_ids, идет самым последним). Сообщили о проблемах в elibrary. К сожалению, вычистить эти данные «простым скриптом» будет неправильным действием, так как среди таких примеров есть и «настоящие» дубликаты. Кроме того, база не предполагает императивных действий по отношению к попавшим в нее, а предполагает изучение ситуации издателем. Примеров, когда у двух статей, сформировавших кластер, id отличаются на единицу относительно немного — около 1000 — несколько процентов от общего числа кластеров.
В-третьих, по поводу последних кластеров. В них действительно должны быть сосредоточены эти ошибки, так как коэффициент совпадения слишком велик — 99-100. А вот проверить глазами можно не всегда, так как издатели не открыли доступ к полным текстам статей. Ну и в целом могу сказать, что реальные данные — это особая стезя. Огромное количество разных ошибок, которые ведут как созданию ложных кластеров, так и к разрушению существующих.
Уважаемый Юрий, можно ли это понимать так, что вы подвергаете сомнению репутации на основе непроверенных данных ?
Нет, это не так. Чью либо репутацию может поставить под сомнение решение редколлегии соответствующих журналов.
К сожалению, не могу с Вами согласиться.
Нет, в статье выше сказано:
>В-пятых, если вы являетесь представителем университета, принимающим управленческие решения, и имена ваших сотрудников оказались в этой базе данных…
То есть вы портите репутацию сотрудника в глазах его начальства и коллег. Причем сразу оправдаться он не может, раз «проверить глазами можно не всегда, так как издатели не открыли доступ к полным текстам статей.» Т.е. несколько процентов авторов пострадают невиновных. Приемлемо ли это с точки зрения вашей этики?
Тем не менее, база содержит случаи добросовестного дублирования, о чем сказано в исходной работе: https://doi.org/10.1016/j.joi.2021.101246. Поэтому в чистом виде попадание в базу не ставит под сомнение репутацию.
Да, действительно — suspicious_ids я не заметил (не промотал до правого края), они в двух случаях из тех трех, про которые я сначала писал, есть. Но я не согласен с двумя вашими утверждениями.
1. «Примеров, когда у двух статей, сформировавших кластер, id отличаются на единицу относительно немного — около 1000».
Во-первых, это много. Во-вторых, много таких статей отличаются на несколько — например, на 5. Посмотрите несколько последних строчек. И этот suspicious_ids там часто 0.
2. И о более главном, с моей точки зрения.
«Кроме того, база не предполагает императивных действий по отношению к попавшим в нее, а предполагает изучение ситуации издателем.»
Чьих действий? Вы ставите людей под подозрение. «Императивные», извиняюсь за выражение, «действия» может ВНЕЗАПНО предпринять, например, наше министерство.
«К сожалению, вычистить эти данные «простым скриптом» будет неправильным действием, так как среди таких примеров есть и «настоящие» дубликаты.»
По-моему, это было бы единственным правильным действием. Есть часть базы, где очевидно много ошибок, ставящих людей под подозрение. Есть этика исследования, все же про живых людей пишете, не про элементарные частицы. Правильно было бы не выкладывать эти очевидные сомнительные записи. В них можно потом потихоньку ковыряться, отделяя одно от другого. Вреда от того, что некоторая часть «настоящих дубликатов» окажется пока не выявлена, по-любому меньше, чем от ошибок другого рода.
Даже если смотреть на это с точки зрения вашей статьи — относительная ошибка числа дублирующих публикаций при этом уменьшится. Хотя, по-моему, это гораздо менее важно, чем вышеизложенное.
Ретрагирование статьи… Пафосно-то как! По-русски: отозвать статью. И не надо изобретать англо-нижегородских терминов.